
An In-Depth Analysis of Buffer Pool in InnoDB
By Kang Wang
1. Preface
Buffer Pool is a vital component of InnoDB and one of the most critical elements for database users. The basic features of Buffer Pool are not complicated, and the design and implementation are clear. However, as an industrial-level database product with a history of decades, it inevitably incorporates more and more features and optimizations in the details, which makes it a bit redundant and obscure.
バッファプールはInnoDBの重要なコンポーネントであり、データベースユーザーにとって最も重要な要素の一つです。バッファプールの基本的な機能は複雑ではなく、その設計と実装も明確です。しかし、数十年の歴史を持つ産業レベルのデータベース製品として、細部にはますます多くの機能や最適化が組み込まれており、そのためやや冗長でわかりにくくなっています。
This article focuses on the features of the Buffer Pool and introduces its interfaces, memory organization, page fetching, and flushing, interspersed with discussions of key optimization strategies. Additionally, a separate section is devoted to the more intricate aspect of concurrency control, particularly the design and implementation of mutexes.
この記事では、バッファプールの機能に焦点を当て、そのインターフェース、メモリ構成、ページの取得とフラッシュ処理について紹介します。また、重要な最適化戦略についても随所で議論します。さらに、並行制御のより複雑な側面、特にミューテックスの設計と実装については別途セクションを設けて解説します。
In addition, although many features such as Change Buffer, page compaction, and Double Write Buffer are interspersed in the implementation of Buffer Pool, they do not belong to the core logic of Buffer Pool. Therefore, this article does not include these features. The relevant code in this article is based on MySQL 8.0.
なお、Change Buffer、ページ圧縮、Double Write Bufferなど、多くの機能がバッファプールの実装内に散在していますが、これらはバッファプールのコアロジックには属しません。したがって、この記事ではこれらの機能は含みません。この記事で扱うコードはMySQL 8.0をベースにしています。
2. Background
Data in traditional databases is completely stored on disks, but computing can only occur in memory. Therefore, a good mechanism is needed to coordinate data interaction between memory and disk. This is the meaning of Buffer Pool. Therefore, Buffer Pool usually manages memory based on a fixed-length page to easily swap in and out data with disks.
従来のデータベースではデータは完全にディスク上に保存されますが、計算処理はメモリ上でしか行えません。したがって、メモリとディスク間のデータのやり取りを効率よく調整する仕組みが必要になります。これがバッファプールの意味です。バッファプールは通常、固定長のページ単位でメモリを管理し、ディスクとのデータの入れ替え(スワップ)を容易にします。
In addition, there is a huge gap between disk and memory access performance. How to minimize disk I/O has become the core design goal of Buffer Pool. As introduced in the article Past and Present of the Recovery Mechanism of Database Failure, mainstream databases use REDO LOG plus UNDO LOG instead of limiting the order of flushing to ensure the ACID (atomicity, consistency, isolation, and durability) of the database. This approach also ensures that the Buffer Pool can focus more on implementing efficient cache policies.
また、ディスクとメモリのアクセス性能には大きな差があります。ディスクI/Oをいかに最小化するかがバッファプール設計の核心的な目標となっています。以前の記事「データベース障害復旧機構の過去と現在」で紹介したように、主流のデータベースはACID(原子性、一貫性、独立性、耐久性)を保証するために、フラッシュの順序を制限する代わりにREDOログとUNDOログを利用しています。このアプローチにより、バッファプールは効率的なキャッシュポリシーの実装に専念できます。
As a whole, the Buffer Pool provides a very simple interface for external users, which is called the FIX-UNFIX interface. The reason why FIX and UNFIX are required is that the Buffer Pool does not know how long it takes for the upper layer to use the page. During this process, it is necessary to ensure that the page is correctly maintained in the Buffer Pool.
バッファプールは外部ユーザーに対して非常にシンプルなインターフェースを提供しており、これを「FIX-UNFIXインターフェース」と呼びます。FIXとUNFIXが必要な理由は、バッファプール側が上位層がページをどのくらいの期間使用するかを知らないためです。この間、ページが正しくバッファプール内に保持される必要があります。
• The upper-layer caller first obtains the page number to be accessed through the index.
上位層の呼び出し元は、まずインデックスを通じてアクセスしたいページ番号を取得します。
• After that, this page number calls the FIX interface of the Buffer Pool to obtain the page and access or modify it. The FIX page will not be swapped out of the Buffer Pool.
次に、そのページ番号を使ってバッファプールのFIXインターフェースを呼び出し、ページを取得してアクセスや修正を行います。FIXされたページはバッファプールからスワップアウトされません。
• After that, the caller releases the locked state of the page through the UNFIX.
最後に、呼び出し元はUNFIXを通じてページのロック状態を解除します。
The string of concurrent calls to the FIX-UNFIX interface of the Buffer Pool by different transactions and different threads is called the page reference string. This string itself is independent of the Buffer Pool but only depends on the load type, load concurrency, upper-layer index implementation, and data model on the database. The Buffer Pool design of the generic database is aimed at achieving the goal of minimizing disk I/O and efficient access with most page reference strings as much as possible.
異なるトランザクションやスレッドが同時にバッファプールのFIX-UNFIXインターフェースを呼び出す一連の操作を「ページ参照列(page reference string)」と呼びます。この参照列はバッファプール自体には依存せず、ロードの種類や並行度、上位層のインデックス実装、データベースのデータモデルに依存します。汎用データベースのバッファプール設計は、できる限り多くのページ参照列に対してディスクI/Oを最小化し効率的にアクセスすることを目標としています。
To achieve this goal, a lot of work has been done within the Buffer Pool, and the replacement algorithm is the most important part. Since the memory capacity is usually much smaller than the disk capacity, the replacement algorithm needs to kick out the existing memory page and replace it with a new referenced page when the memory capacity reaches the upper limit. A good replacement algorithm can minimize the occurrence of Buffer Miss at a given Buffer Size.
この目標を達成するために、バッファプール内部では多くの工夫がなされており、その中でも「置換アルゴリズム」が最も重要な部分です。メモリ容量は通常ディスク容量よりはるかに小さいため、メモリ容量が上限に達した際には既存のメモリページを追い出して新たに参照されたページを読み込む必要があります。良い置換アルゴリズムは、与えられたバッファサイズでバッファミスの発生を最小化します。
Ideally, we replace the farthest page in the future reference string each time, which is also the idea of the OPT algorithm, but it is impractical to obtain the future page string, so the OPT algorithm is just an ideal model as an optimal boundary for judging the replacement algorithm. In contrast, the random algorithm which is the worst boundary is based on completely random replacement.
理想的には、将来の参照列の中で最も先に参照されるページを置換します。これはOPTアルゴリズムの考え方ですが、将来の参照列を事前に知ることは不可能なため、OPTはあくまで理想モデルとして置換アルゴリズムの最適境界を示すものです。一方、ランダムアルゴリズムは最悪境界であり、完全にランダムに置換を行います。
(補足:OPT(Optimal Page Replacement Algorithm)
将来、最も長い期間使われないページを置き換える(スワップアウトする)アルゴリズムです。)
In most cases, page references are popularity-differentiated, which makes it possible for the replacement algorithm to determine the future string through the historical string. There are usually two indicators to refer to:
多くの場合、ページ参照は人気度に差があるため、過去の参照列から将来の参照を推測することが可能です。主に以下の2つの指標が使われます。
- Age: in the page reference string, the distance of the last reference to a page to the current reference.
Age:ページが最後に参照された時点から現在までの距離 - References: the number of times a page has been referenced in history or in a period of time.
References(参照回数):過去または一定期間内にページが参照された回数
Both the FIFO (First In First Out) algorithm which only considers the access distance and the LFU (Least Frequently Used) algorithm which only considers the number of references are flawed in particular strings. A good practical replacement algorithm should consider both of the two indicators. Such algorithms include the LRU (Least Recently Used) algorithm and the Clocks algorithm.
単にアクセス距離だけを考慮するFIFO(First In First Out)や、参照回数だけを考慮するLFU(Least Frequently Used)は特定の参照列では欠点があります。実用的な置換アルゴリズムはこれら両方の指標を考慮すべきであり、代表的なものにLRU(Least Recently Used)やClockアルゴリズムがあります。
This article then introduces in detail the implementation of the LRU replacement algorithm in InnoDB, in addition to how to implement efficient page lookup, memory management, flushing strategy, and concurrent access to pages.
この記事では、InnoDBにおけるLRU置換アルゴリズムの実装を詳しく紹介するとともに、効率的なページ検索、メモリ管理、フラッシュ戦略、ページの並行アクセスの実装方法についても解説します。
3. Usage
First, let’s look at how the features of Buffer Pool are used in InnoDB.
In the two articles B+ Tree Database Locking History and B+ Tree Database Fault Recovery Overview, it is pointed out that in order to achieve higher transaction concurrency, B+ tree databases distinguish logical content and physical content in concurrency control and fault recovery. Physical content refers to access to pages, while a logical transaction can initiate and submit multiple system transactions at different times. System transactions will be submitted in a short time without rollback. Usually, only a few pages are involved, such as parent and child nodes, data nodes, and undo nodes that are split or merged. System transactions use Redo + No Steal to ensure the Crash Safe of multiple pages. Latch, which is lighter than Lock, is used to ensure secure concurrent access between different system transactions.
「B+ツリーのデータベースロックの歴史」と「B+ツリーのデータベース障害復旧の概要」という2つの記事では、高いトランザクション並行性を実現するために、B+ツリーデータベースは並行制御や障害復旧において論理的な内容と物理的な内容を区別していることが指摘されています。物理的な内容とはページへのアクセスを指し、論理トランザクションは複数のシステムトランザクションを異なるタイミングで開始・コミットすることができます。システムトランザクションはロールバックせず短時間でコミットされ、通常は親子ノードやデータノード、分割や結合が行われるundoノードなど、数ページのみが関与します。システムトランザクションはRedoログとNo Steal方式を用いて複数ページのクラッシュセーフを保証します。また、ロックより軽量なラッチを使い、異なるシステムトランザクション間の安全な並行アクセスを実現しています。
In short, system transactions need to obtain several different pages in sequence, add a latch to the obtained pages, use or modify pages, and write redo logs to ensure the atomicity of multiple page accesses. In InnoDB, this system transaction is the MTR (Mini-Transaction). Buffer Pool provides the interface for obtaining the corresponding page through Page No. Therefore, it can be said that in InnoDB MTR is mainly used for Buffer Pool.
簡単に言うと、システムトランザクションは複数の異なるページを順番に取得し、取得したページにラッチをかけてページを使用または変更し、複数ページアクセスの原子性を保証するためにRedoログを書き込みます。InnoDBではこのシステムトランザクションをMTR(Mini-Transaction)と呼びます。バッファプールはページ番号を通じて対応するページを取得するインターフェースを提供しているため、InnoDBにおいてMTRは主にバッファプールのために使われていると言えます。
1. The Upper Layer Calls buf_page_get_gen to Obtain the Required Page
The following is the code for the upper layer to obtain the required page through Buffer Pool. buf_page_get_gen interface corresponds to the FIX interface mentioned above:
以下は、上位層がバッファプールを通じて必要なページを取得するためのコードです。buf_page_get_gen インターフェースは、前述のFIXインターフェースに対応しています。
buf_block_t* block = buf_page_get_gen(page_id, page_size, rw_latch, guess, buf_mode, mtr);The buf_block_t is the memory management structure corresponding to the page, and the complete page content can be accessed through the block->frame pointer. The first parameter page_id specifies the required page number, and this page_id is usually obtained through the upper B Tree retrieval. The third parameter rw_latch specifies the read-write Latch mode to be added to the page. The last parameter MTR is the Mini-Transaction mentioned above. When the same MTR accesses multiple pages, this MTR structure is passed on each call to buf_page_get_gen.
buf_block_t はページに対応するメモリ管理構造体であり、block->frame ポインタを通じてページの完全な内容にアクセスできます。
最初のパラメータ page_id は必要なページ番号を指定し、この page_id は通常、上位のBツリー検索を通じて取得されます。
3番目のパラメータ rw_latch はページに付加する読み書きラッチのモードを指定します。
最後のパラメータ MTR は前述のMini-Transaction(ミニトランザクション)であり、同じMTRが複数ページにアクセスする場合、このMTR構造体が buf_page_get_gen の各呼び出しに渡されます。
2. Obtain the Page Inside buf_page_get_gen and Mark FIX and Lock It
In the buf_page_get_gen, the required page needs to be obtained first. This process will be described in detail later. After that, two things will be cleared: mark the FIX state of the page (page->buf_fix_count) to prevent it from being swapped out, and add the corresponding rw_latch mode lock (block->lock) to the page.
buf_page_get_genにおいて、まず必要なページを取得する必要があります。このプロセスについては後ほど詳しく説明します。その後、2つの処理が行われます。
- ページのFIX状態をマークする(page->buf_fix_count):
これにより、ページがスワップアウトされないようにします。 - ページに対応するrw_latchモードロック(block->lock)を追加する:
これにより、ページへのアクセス制御を行います。
./* 1. Mark the FIX state of the page to prevent it from being swapped out. Here, a counter buf_fix_count */ buf_block_fix (fix_block) on the page structure is used.
.../* 2. Add a latch corresponding to the rw_latch mode, that is, the lock on the block to the page */mtr_memo_type_t fix_type;switch (rw_latch) {
... case RW_S_LATCH:
rw_lock_s_lock_inline(&fix_block->lock, 0, file, line);
fix_type = MTR_MEMO_PAGE_S_FIX; break;
...
}/* The last block pointer and the locking mode are also recorded in the MTR structure to facilitate the release when MTR is committed */mtr_memo_push(mtr, fix_block, fix_type);
...3. Release the Lock When MTR Is Committed
The MTR structure contains one or more pages that already hold the lock. When the MTR is committed, perform the UNFIX together and release the lock:
MTR構造体には、すでにロックがかかっている1つ以上のページが含まれています。MTRがコミットされると、UNFIX(ロック解除)をまとめて実行し、ロックを解放します。
static void memo_slot_release(mtr_memo_slot_t *slot) { switch (slot->type) {
buf_block_t *block; case MTR_MEMO_BUF_FIX: case MTR_MEMO_PAGE_S_FIX: case MTR_MEMO_PAGE_SX_FIX: case MTR_MEMO_PAGE_X_FIX:
block = reinterpret_cast<buf_block_t *>(slot->object); /* 1. UNFIX the page, that is, buf_fix_count-- */
buf_block_unfix(block); /* 2. Release the lock of the page, block->lock */
buf_page_release_latch(block, slot->type); break;
...
}
...
}This section has introduced how InnoDB uses the interface provided by Buffer Pool to access pages. Before specifically describing how to maintain pages to support efficient search and flushing, let’s first understand the organizational structure of Buffer Pool as a whole.
このセクションでは、InnoDBがBuffer Poolが提供するインターフェースを使ってページにアクセスする方法について紹介しました。効率的な検索やフラッシュをサポートするためにページをどのように管理するかを具体的に説明する前に、まずBuffer Pool全体の構成について理解しておきましょう。
4. Organizational Structure
To reduce concurrent access conflicts, InnoDB divides the Buffer Pool into innodb_buffer_pool_instances Buffer Pool instances. There is no lock conflict between instances, and each page belongs to one of the instances. In terms of structure, each instance is equivalent. Therefore, the following content is described from the perspective of one instance.
同時アクセスの競合を減らすため、InnoDB はバッファープールを innodb_buffer_pool_instances バッファープールインスタンスに分割します。インスタンス間のロック競合はなく、各ページはいずれかのインスタンスに属します。構造的には、各インスタンスは同等です。そのため、以下の内容は 1 つのインスタンスの観点から説明されています。
Block, Page, and Chunk
Buffer Pool divides the allocated memory into blocks with equal size and allocates a memory management structure buf_block_t for each block to maintain block-related state information, locking information, and memory data structure pointers. Blocks are the carrier of pages in memory. In many scenarios, a block is a page. According to the code, buf_block_t starts with buf_page_t which maintains page information (including page_id, modified lsn information oldest_modification, and newest_modification) so that they can be directly and explicitly converted:
バッファプールは、割り当てられたメモリを同じサイズのブロックに分割し、各ブロックにメモリ管理構造体 buf_block_t を割り当てて、ブロック関連の状態情報、ロック情報、およびメモリデータ構造ポインタを維持します。ブロックはメモリ内のページの運搬手段です。多くのシナリオでは、ブロックはページです。このコードによると、buf_block_t は buf_page_t で始まり、ページ情報 (page_id、変更された lsn 情報 oldest_modification、newest_modification など) が管理され、直接かつ明示的に変換できるようになっています。
struct buf_block_t {
buf_page_t page; /*!< page information; this must
be the first field, so that
buf_pool->page_hash can point
to buf_page_t or buf_block_t */
...
}A single buf_block_t requires several hundred bytes of storage. Taking a 100 GB Buffer Pool and a 16 KB page size as an example, there will be 6 MB blocks, and the memory usage of such a large number of buf_block_t is also very considerable. To facilitate the allocation and management of this part of memory, InnoDB splices it directly into the block array. This is also the reason why the actual memory usage of Buffer Pool will be slightly larger than the configured innodb_buffer_pool_size. Later, to facilitate online resizing, Buffer Pool divided the memory into 128 MB chunks by default from version 5.7. Each chunk has the following memory structure:
1 つの buf_block_t には数百バイトのストレージが必要です。100 GB のバッファープールと 16 KB のページサイズを例にとると、6 MB のブロックがあり、このような大量の buf_block_t のメモリー使用量も非常に大きくなります。メモリのこの部分の割り当てと管理を容易にするために、InnoDB ではこの部分をブロック配列に直接接続します。これが、バッファープールの実際のメモリー使用量が、設定された innodb_buffer_pool_size よりもわずかに大きくなる理由でもあります。その後、オンラインでのサイズ変更が容易になるように、バージョン 5.7 以降、バッファープールはメモリをデフォルトで 128 MB のチャンクに分割しました。各チャンクのメモリー構造は以下のとおりです。
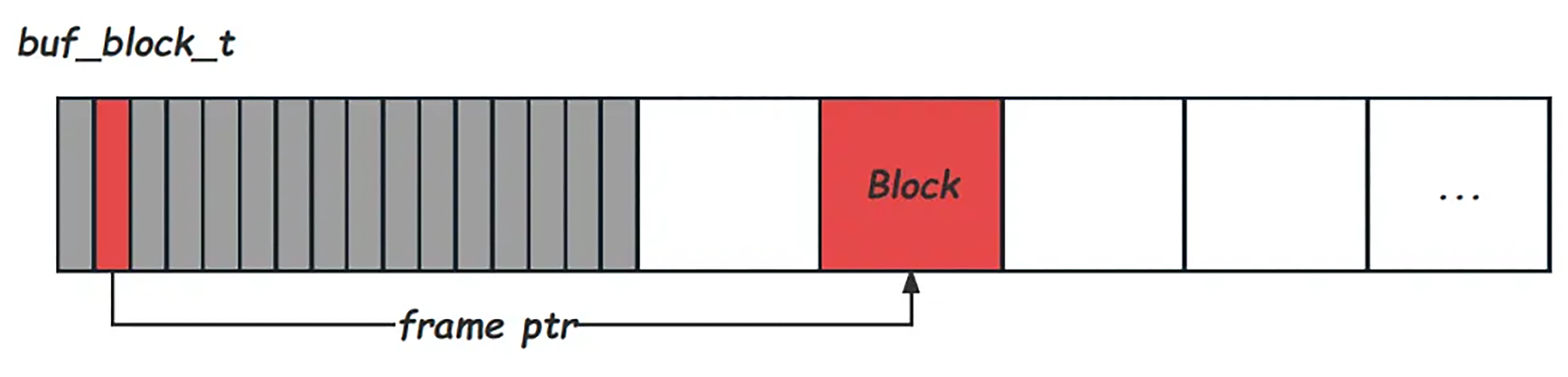
At startup, the buf_chunk_init function allocates all the memory required by Buffer Pool through mmap, so InnoDB does not really take up such a large amount of physical memory at startup, but it will increase with the allocation of pages. In addition, since the memory address of each block is required to be aligned according to the page size and buf_block_t does not necessarily have a divisor relationship with the page size, there may be some memory fragments that will not be used before the page array.
起動時に、buf_chunk_init 関数はバッファープールに必要なすべてのメモリを mmap 経由で割り当てるため、InnoDB は起動時にそれほど大量の物理メモリを消費しませんが、ページの割り当てとともに増加します。さらに、各ブロックのメモリアドレスはページサイズに合わせて揃える必要があり、buf_block_t は必ずしもページサイズと除数関係にあるわけではないため、ページ配列の前には使用されないメモリフラグメントが存在する可能性があります。
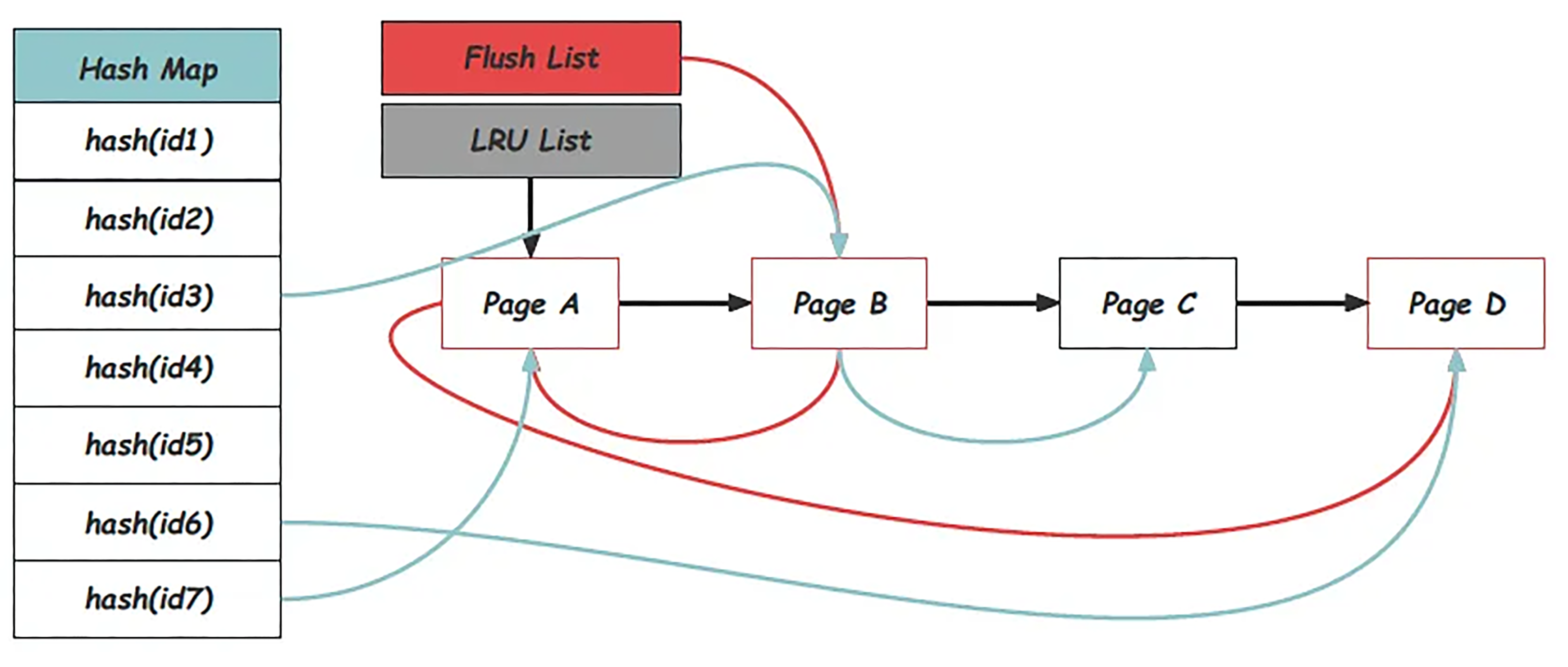
Hash Map, LRU List, Free List, and Flush List
From the usage point of view, it is a centralized and frequent operation to call the interface buf_page_get_gen with the specified page_id. InnoDB uses a Hash Map from page_id to blocks to support efficient queries. All pages in the Buffer Pool can be found in the Hash Map. This Hash Map is implemented in the form of chain conflict and is accessed through the page_hash pointer in buf_pool_t.
使い方の観点から見ると、指定された page_id で buf_page_get_gen インターフェイスを呼び出すのは、一元化された頻繁な操作です。InnoDB は page_id からのハッシュマップを使用してブロックし、効率的なクエリをサポートします。バッファープール内のすべてのページはハッシュマップにあります。このハッシュマップはチェーンコンフリクトという形で実装されており、buf_pool_t の page_hash ポインターを介してアクセスされます。
In addition, the Buffer Pool also maintains many trace lists in memory to manage blocks, of which the LRU List undertakes the role of the stack in the LRU replacement algorithm. Blocks will be moved to the header of the LRU List when accessed, while pages that have not been accessed for a long time will be gradually pushed to the tail position of the LRU List until it is swapped out.
さらに、バッファープールはブロックを管理するための多数のトレースリストをメモリに保持します。LRUリストは、LRU置換アルゴリズムにおけるスタックの役割を果たします。ブロックはアクセスされるとLRUリストのヘッダーに移動され、長期間アクセスされていないページはスワップアウトされるまでLRUリストの末尾に徐々に移動されます。
The Free List maintains unused blocks. Each block must exist on the LRU List or the Free List at the same time. Modified pages are called dirty pages in InnoDB, and dirty pages need to be flushed when appropriate. To obtain the location of the checkpoint, it is necessary to push the smallest dirty page location that has not been flushed. Therefore, a dirty page sequence ordered by oldest_modification is required. This is the meaning of the Flush List. Dirty pages must be blocks in use, so they must also be on the LRU List. The entire memory structure is shown in the following figure:
フリーリストには未使用のブロックが保存されます。各ブロックは LRU リストまたはフリーリストに同時に存在しなければなりません。変更されたページは InnoDB ではダーティページと呼ばれ、ダーティページは必要に応じてフラッシュする必要があります。チェックポイントの場所を取得するには、フラッシュされていない最も小さいダーティページの位置をプッシュする必要があります。そのため、oldest_modification で順序付けられたダーティ・ページ・シーケンスが必要です。これがフラッシュリストの意味です。ダーティページは使用中のブロックでなければならないため、LRU リストにも含まれている必要があります。メモリー構造全体を次の図に示します。

コメント