
Source : The physical structure of InnoDB index pages
The physical structure of InnoDB index pages
In On learning InnoDB: A journey to the core, I introduced the innodb_diagrams project to document the InnoDB internals, which provides the diagrams used in this post. (Note that each image below is linked to a higher resolution version of the same image.)
「InnoDB の学習について:コアへの道のり」で、InnoDB の内部構造を文書化する innodb_diagramsプロジェクトを紹介しました。このプロジェクトでは、この記事で使用したダイアグラムを提供しています。(以下の各イメージは、同じイメージの高解像度バージョンにリンクされていることに注意してください。)
The basic structure of the space and each page was described in The basics of InnoDB space file layout, and we’ll now take a deeper look into how INDEX pages are physically structured. This will lay the ground work to discuss indexes at a logical (and much higher) level.
スペースと各ページの基本構造は、「InnoDB スペースファイルレイアウトの基本」で説明しました。次に、INDEX ページが物理的にどのように構造化されているかを詳しく見ていきます。これにより、論理的な (そしてはるかに高い) レベルでインデックスを説明するための基礎が築かれます。
Everything is an index in InnoDB
Before diving into physical structures, it’s critical to understand that in InnoDB, everything is an index. What does that mean to the physical structure?
物理構造に飛び込む前に、InnoDB ではすべてがインデックスであることを理解することが重要です。これは物理構造にとってどのような意味を持つのでしょうか?
- Every table has a primary key; if the CREATE TABLE does not specify one, the first non-NULL unique key is used, and failing that, a 48-bit hidden “Row ID” field is automatically added to the table structure and used as the primary key. Always add a primary key yourself. The hidden one is useless to you but still costs 6 bytes per row.
- すべてのテーブルには主キーがあります。CREATE TABLE で主キーが指定されていない場合は、NULL 以外の最初の一意キーが使用され、それができない場合は、48 ビットの非表示の「行 ID」フィールドがテーブル構造に自動的に追加され、主キーとして使用されます。主キーは必ず自分で追加してください。隠しキーは役に立たないが、それでも1行あたり6バイトのコストがかかる。
- The “row data” (non-PRIMARY KEY fields) are stored in the PRIMARY KEY index structure, which is also called the “clustered key”. This index structure is keyed on the PRIMARY KEY fields, and the row data is the value attached to that key (as well as some extra fields for MVCC).
- 「行データ」(非主キーフィールド) は、「クラスタ化キー」とも呼ばれる PRIMARY KEY インデックス構造に保存されます。このインデックス構造は PRIMARY KEY フィールドをキーとしており、行データはそのキーに付けられた値です (MVCC の場合はいくつかの追加フィールドも同様)。
- Secondary keys are stored in an identical index structure, but they are keyed on the KEY fields, and the primary key value (PKV) is attached to that key.
- セカンダリキーは同じインデックス構造に格納されますが、キーフィールドでキーが設定され、プライマリキー値 (PKV) がそのキーに添付されます。
When discussing “indexes” in InnoDB (as in this post), this actually means both tables and indexes as the DBA may think of them.
InnoDBの「インデックス」(この記事のように)について説明する場合、これは実際にはDBAが考えるかもしれないテーブルとインデックスの両方を意味します。
Overview of INDEX page structure
Every index page has an overall structure as follows:
すべての索引ページは、次のような全体的な構造になっています。
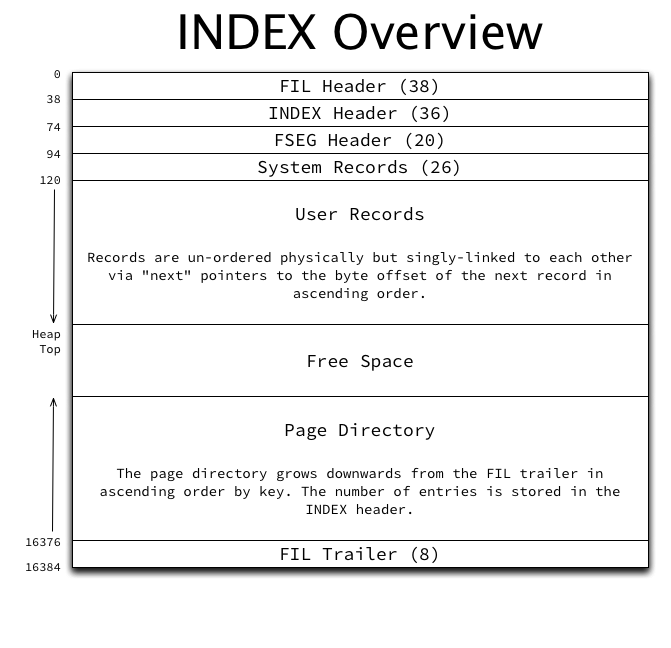
The major sections of the page structure are (not in order):
- The FIL header and trailer: This is typical and common to all page types. One aspect somewhat unique to INDEX pages is that the “previous page” and “next page” pointers in the FIL header point to the previous and next pages at the same level of the index, and in ascending order based on the index’s key. This forms a doubly-linked list of all pages at each level. This will be further described in the logical index structure.
- FIL ヘッダーとトレーラー:これは一般的なもので、すべてのページタイプに共通です。INDEX ページ特有の側面の 1 つは、FIL ヘッダーの「前のページ」と「次のページ」のポインタが、インデックスのキーに基づいて昇順でインデックスの同じレベルにある前のページと次のページを指していることです。これにより、各レベルの全ページが二重にリンクされたリストになります。これについては、論理索引構造で詳しく説明します。
- The FSEG header: As described in Page management in InnoDB space files, the index root page’s FSEG header contains pointers to the file segments used by this index. All other index pages’ FSEG headers are unused and zero-filled.
- FSEG ヘッダー:InnoDB スペースファイルのページ管理で説明されているように、インデックスルートページの FSEG ヘッダーには、このインデックスで使用されるファイルセグメントへのポインターが含まれています。他のすべてのインデックスページの FSEG ヘッダーは使用されず、ゼロで埋められます。
- The INDEX header: Contains many fields related to INDEX pages and record management. Fully described below.
- INDEX ヘッダー:INDEX ページとレコード管理に関連する多くのフィールドが含まれています。以下で詳しく説明します。
- System records: InnoDB has two system records in each page called infimum and supremum. These records are stored in a fixed location in the page so that they can always be found directly based on byte offset in the page.
- システムレコード:InnoDB の各ページには、「infimum」と「supremum」という 2 つのシステムレコードがあります。これらのレコードはページ内の固定された場所に保存されるため、ページ内のバイトオフセットに基づいていつでも直接見つけることができます。
- User records: The actual data. Every record has a variable-width header and the actual column data itself. The header contains a “next record” pointer which stores the offset to the next record within the page in ascending order, forming a singly-linked list. Details of user record structure will be described in a future post.
- ユーザーレコード:実際のデータ。すべてのレコードには可変幅のヘッダーと実際の列データ自体があります。ヘッダーには、ページ内の次のレコードへのオフセットを昇順で格納する「次のレコード」ポインタがあり、単一リンクリストを形成します。ユーザーレコード構造の詳細は、今後の投稿で説明します。
- The page directory: The page directory grows downwards from the “top” of the page starting at the FIL trailer and contains pointers to some of the records in the page (every 4th to 8th record). Details of the page directory logical structure and its purpose will be described in a future post.
- ページディレクトリ:ページディレクトリは FIL トレーラーからページの「上部」から下に向かって展開され、ページ内の一部のレコードへのポインタを含んでいます (4 ~ 8 レコードごと)。ページディレクトリの論理構造とその目的の詳細は、今後の投稿で説明します。
The INDEX header
The INDEX header in each INDEX page is fixed-width and has the following structure:
各 INDEX ページの INDEX ヘッダーは固定幅で、次のような構造になっています。

The fields stored in this structure are (not in order):
- Index ID: The ID of the index this page belongs to.
- インデックス ID: このページが属するインデックスのID。
- Format Flag: The format of the records in this page, stored in the high bit (0x8000) of the “Number of Heap Records” field. Two values are possible: COMPACT and REDUNDANT. Described fully below.
- フォーマットフラグ:このページのレコードのフォーマット。「ヒープレコード数」フィールドの上位ビット (0x8000) に保存されます。[コンパクト] と [冗長] の 2 つの値を指定できます。以下で詳しく説明します。
- Maximum Transaction ID: The maximum transaction ID of any modification to any record in this page.
- 最大トランザクションID: このページの任意のレコードへの変更の最大トランザクションID。
- Number of Heap Records: The total number of records in the page, including the infimum and supremum system records, and garbage (deleted) records.
- ヒープレコード数:最小システムレコードと最高システムレコード、およびガベージレコード (削除済み) レコードを含む、ページ内のレコードの総数。
- Number of Records: The number of non-deleted user records in the page.
- レコード数:ページ内の削除されていないユーザーレコードの数。
- Heap Top Position: The byte offset of the “end” of the currently used space. All space between the heap top and the end of the page directory is free space.
- ヒープトップポジション:現在使用されているスペースの「終わり」のバイトオフセット。ヒープ上部とページディレクトリの末尾の間のスペースはすべて空き領域です。
- First Garbage Record Offset: A pointer to the first entry in the list of garbage (deleted) records. The list is singly-linked together using the “next record” pointers in each record header. (This is called “free” within InnoDB, but this name is somewhat confusing.)
- 最初のガベージレコードオフセット:ガベージ (削除された) レコードのリストの最初のエントリへのポインタ。リストは、各レコードヘッダーの「次のレコード」ポインタを使用して単独でリンクされます。(これは InnoDB では「free」と呼ばれていますが、この名前はややわかりにくいです)。
- Garbage Space: The total number of bytes consumed by the deleted records in the garbage record list.
- ガベージスペース:ガベージレコードリスト内の削除されたレコードによって消費されたバイトの総数。
- Last Insert Position: The byte offset of the record that was last inserted into the page.
- 最終挿入位置:ページに最後に挿入されたレコードのバイトオフセット。
- Page Direction: Three values are currently used for page direction: LEFT, RIGHT, and NO_DIRECTION. This is an indication as to whether this page is experiencing sequential inserts (to the left [lower values] or right [higher values]) or random inserts. At each insert, the record at the last insert position is read and its key is compared to the currently inserted record’s key, in order to determine insert direction.
- ページ方向:現在、ページの方向には「左」、「右」、「NO_DIRECTION」の 3 つの値が使用されています。これは、このページで連続挿入 (左 [低い値] または右 [高い値]) が行われているのか、それともランダムに挿入されているのかを示します。挿入のたびに、最後の挿入位置のレコードが読み込まれ、そのキーが現在挿入されているレコードのキーと比較して、挿入方向が決定されます。
- Number of Inserts in Page Direction: Once the page direction is set, any following inserts that don’t reset the direction (due to their direction differing) will instead increment this value.
- ページ方向への挿入数:ページの方向が設定されると、それ以降の挿入で (方向が異なるために) 方向がリセットされない場合は、代わりにこの値が増加します。
- Number of Directory Slots: The size of the page directory in “slots”, which are each 16-bit byte offsets.
- ディレクトリスロットの数:「スロット」内のページディレクトリのサイズ。それぞれ16ビットバイトのオフセットです。
- Page Level: The level of this page in the index. Leaf pages are at level 0, and the level increments up the B+tree from there. In a typical 3-level B+tree, the root will be level 2, some number of internal non-leaf pages will be level 1, and leaf pages will be level 0. This will be discussed in more detail in a future post as it relates to logical structure.
- ページレベル:インデックス内のこのページのレベル。リーフページはレベル 0 で、そこから B+ ツリーのレベルが上がります。一般的な 3 レベルの B+Tree では、ルートはレベル 2、内部非リーフページの一部はレベル 1、リーフページはレベル 0 になります。これについては、論理構造に関連するので、今後の投稿でさらに詳しく説明します。
Record format: redundant versus compact
The COMPACT record format is new in the Barracuda table format, while the REDUNDANT record format is the original one in the Antelope table format (neither of which had a name officially until Barracuda was created). The COMPACT format mostly eliminated information that was redundantly stored in each record and can be obtained from the data dictionary, such as the number of fields, which fields are nullable, and which fields are dynamic length.
COMPACT レコード形式はバラクーダテーブル形式では新しく、REDUNDANT レコード形式は元々の Antelope テーブル形式です (どちらも Barracuda が作成されるまで正式には名前がありませんでした)。COMPACT 形式では、フィールド数、NULL 値が許容されるフィールド、動的長さのフィールドなど、各レコードに重複して格納され、データディクショナリから取得できる情報がほとんど削除されました。
An aside on record pointers
Record pointers are used in several different places: the Last Insert Position field in the INDEX header, all values in the page directory, and the “next record” pointers in the system records and user records. All records contain a header (which may be variable-width) followed by the actual record data (which may also be variable-width). Record pointers point to the location of the first byte of record data, which is effectively “between” the header and the record data. This allows the header to be read by reading backwards from that location, and the record data to be read forward from that location.
レコードポインタは、INDEX ヘッダの Last Insert Position フィールド、ページディレクトリ内のすべての値、システムレコードとユーザレコードの「次のレコード」ポインタなど、さまざまな場所で使用されます。すべてのレコードにはヘッダー (可変幅の場合もあります) があり、その後に実際のレコードデータ (可変幅の場合もあります) が続きます。レコードポインタは、レコードデータの最初のバイトの位置、つまり実質的にはヘッダーとレコードデータの「間」の位置を指します。これにより、ヘッダーはその場所から逆方向に読み取り、レコードデータはその場所から順方向に読み取ることができます。
Since the “next record” pointer in system and user records is always the first field in the header reading backwards from this pointer, this means it is also possible to very efficiently read through all records in a page without having to parse the variable-width record data at all.
システムレコードとユーザーレコードの「次のレコード」ポインターは、常にこのポインターから逆方向に読み取るヘッダーの最初のフィールドであるため、可変幅のレコードデータをまったく解析しなくても、ページ内のすべてのレコードを非常に効率的に読み取ることができます。
System records: infimum and supremum
Every INDEX page contains two system records, called infimum and supremum, at fixed locations (offset 99 and offset 112 respectively) within the page, with the following structure:
すべての INDEX ページには、ページ内の固定位置 (それぞれオフセット 99 とオフセット 112) に inimum と premum と呼ばれる 2 つのシステムレコードが次の構造で含まれています。
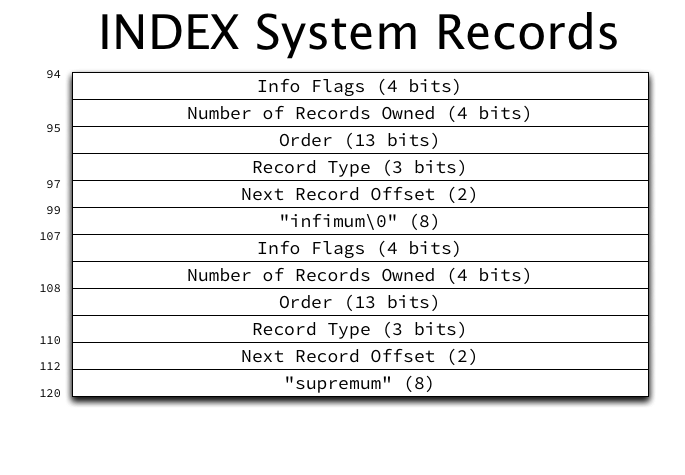
The two system records have a typical record header preceding their location, and the literal strings “infimum” and “supremum” as their only data. A full description of record header fields will be provided in a future post. For now, it is important primarily to observe that the first field (working backwards from the record data, as previously described) is the “next record” pointer.
2 つのシステムレコードには、その位置の前に一般的なレコードヘッダーがあり、データとしてリテラル文字列「infimum」と「supremum」しかありません。レコードヘッダーフィールドの詳細については、今後の投稿で説明します。とりあえず、最初のフィールド (前に説明したように、レコードデータから逆方向に移動する) が「次のレコード」ポインタであることに注意してください。
The infimum record
The infimum record represents a value lower than any possible key in the page. Its “next record” pointer points to the user record with the lowest key in the page. Infimum serves as a fixed entry point for sequentially scanning user records.
下限レコードは、ページ内のどのキーよりも低い値を表します。その「次のレコード」ポインタは、ページ内で最も低いキーを持つユーザーレコードを指します。Infimumは、ユーザーレコードを順次スキャンするための固定エントリポイントとして機能します。
The supremum record
The supremum record represents a key higher than any possible key in the page. Its “next record” pointer is always zero (which represents NULL, and is always an invalid position for an actual record, due to the page headers). The “next record” pointer of the user record with the highest key on the page always points to supremum.
最高レコードは、ページ内のどのキーよりも上位のキーを表します。その「次のレコード」ポインタは常にゼロです (これは NULL を表し、ページヘッダが原因で実際のレコードでは常に無効な位置になります)。ページ上で最も高いキーを持つユーザレコードの「次のレコード」ポインタは、常に premum を指します。
User records
The actual on-disk format of user records will be described in a future post, as it is fairly complex and will require a lengthy explanation itself.
ユーザーレコードの実際のディスク上の形式については、かなり複雑で長い説明が必要になるため、今後の投稿で説明します。
User records are added to the page body in the order they are inserted (and may take existing free space from previously deleted records), and are singly-linked in ascending order by key using the “next record” pointers in each record header. A singly-linked list is formed from infimum, through all user records in ascending order, and terminating at supremum. Using this list, it is trivial to scan in through all user records in a page in ascending order.
ユーザーレコードは、挿入された順序でページ本文に追加され(以前に削除されたレコードから既存の空き領域が取られる場合があります)、各レコードヘッダーの「次のレコード」ポインターを使用してキーごとに昇順で単一リンクされます。単一リンクリストは、最小レコードからすべてのユーザーレコードを昇順に並べて作成され、最上位で終了します。このリストを使用すると、ページ内のすべてのユーザーレコードを昇順で調べるのは簡単です。
Further, using the “next page” pointer in the FIL header, it’s easy to scan from page to page through the entire index in ascending order. This means an ascending-order table scan is also trivial to implement:
さらに、FIL ヘッダーの「次のページ」ポインターを使用すると、インデックス全体を昇順でページからページへと簡単にスキャンできます。つまり、昇順のテーブルスキャンを実装するのも簡単です。
- Start at the first (lowest key) page in the index. (This page is found through B+tree traversal, which will be described in a future post.)
- 索引の最初の (最下位の) ページから開始します。(このページは B+tree トラバーサルで確認できます。これについては、今後の投稿で説明します。)
- Read infimum, and follow its “next record” pointer.
- infimum を読み込み、その「次のレコード」ポインタをたどってください。
- If the record is supremum, proceed to step 5. If not, read and process the record contents.
- レコードが最上位の場合は、手順 5 に進みます。そうでない場合は、レコードの内容を読んで処理してください。
- Follow the “next record” pointer and return to step 3.
- 「次のレコード」ポインタをたどり、手順3に戻ります。
- If the “next page” pointer points to NULL, exit. If not, follow the “next page” pointer and return to step 2.
- 「次のページ」ポインタが NULL を指している場合、終了します。そうでない場合は、「次のページ」ポインタをたどって手順 2 に戻ってください。
Since records are singly-linked rather than doubly-linked, traversing the index in descending order is not as trivial, and will be discussed in a future post.
レコードは二重リンクではなく単一リンクなので、降順でインデックスをトラバースするのはそれほど簡単ではありません。今後の投稿で説明します。
The page directory
The page directory starts at the FIL trailer and grows “downwards” from there towards the user records. The page directory contains a pointer to every 4-8 records, in addition to always containing an entry for infimum and supremum.
ページディレクトリはFILトレーラーから始まり、そこから「下へ」ユーザーレコードに向かって大きくなります。ページディレクトリには、最下位と最上位のエントリが常に含まれていることに加えて、4 ~ 8 レコードごとにポインタが含まれています。

The page directory is simply a dynamically-sized array of 16-bit offset pointers to records within the page. Its purpose will be more fully described in a future post dedicated to the page directory.
ページディレクトリは、ページ内のレコードへの 16 ビットオフセットポインタの動的サイズの配列です。その目的については、ページディレクトリに関する今後の記事で詳しく説明する予定です。
Free space
The space between the user records (which grow “upwards”) and the page directory (which grows “downwards”) is considered free space. Once the two sections meet in the middle, exhausting the free space (and assuming no space can be reclaimed by re-organizing to remove the garbage) the page is considered full.
ユーザーレコード (「上へ」大きくなる) とページディレクトリ (「下へ」大きくなる) の間のスペースは空きスペースとみなされます。2 つのセクションが中央で合流し、空き領域がなくなると (そして、再編成してゴミを取り除いても空き領域がなくなると仮定した場合)、ページは満杯とみなされます。
What’s next?
Next we’ll look at the logical structure of an index, including some examples.
次に、いくつかの例を挙げてインデックスの論理構造を見ていきます。


コメント