
はじめに
この記事では、MySQL InnoDBのBuffer Poolの内部実装を深掘りします。
Buffer Poolはデータベースの性能を左右する最重要コンポーネントです。前回の記事(InnoDB Buffer Pool の仕組みを日本語で理解する)では概要を紹介しましたが、今回はMySQL 8.0のソースコードを追いながら、以下を解説します:
- ページの取得からロック・解放までの一連の流れ
- メモリ上のデータ構造(Hash Map、LRU List、Free List、Flush List)
- LRU置換アルゴリズムの工夫(スキャン耐性)
- ダーティページのフラッシュ戦略と計算式
- 同時実行制御(4種類のロックとデッドロック回避)
元ネタは引き続き Kang Wang 氏の An In-Depth Analysis of Buffer Pool in InnoDB です。この素晴らしい記事を日本語で理解し直すために、自分なりに再度噛み砕いて書き直しをチャレンジしました。
そもそもBuffer Poolって何?
データベースのデータはすべてディスクに保存されています。でも、CPUが計算できるのはメモリ上のデータだけです。
ここに大きな問題があります:
- メモリのアクセス速度:約100ナノ秒
- ディスク(SSD)のアクセス速度:約100マイクロ秒(メモリの約1,000倍遅い)
つまり、毎回ディスクからデータを読んでいたら遅すぎるわけです。
そこで登場するのがBuffer Pool。よく使うデータをメモリ上にキャッシュしておいて、ディスクアクセスを最小限にする仕組みです。
たとえるなら図書館です:
- ディスク = 巨大な書庫(何百万冊あるけど、取りに行くのに時間がかかる)
- Buffer Pool = カウンター横の「よく借りられる本」棚(すぐ手に取れる)
- ページ = 本1冊(InnoDBではデフォルト16KBの固定サイズ)
Buffer Poolの設計目標はシンプルで、ディスクI/Oを最小化すること。これだけです。
Buffer Poolの基本インターフェース:FIX-UNFIX
Buffer Poolが外部に提供するインターフェースは、学術的にはFIX-UNFIXと呼ばれます。図書館でいうと「本を借りる(FIX)→ 読む → 返す(UNFIX)」です。
なぜFIX/UNFIXが必要かというと、Buffer Poolは「上のレイヤーがそのページをいつまで使うか」を知らないからです。使用中のページが勝手にメモリから追い出されたら困りますよね。FIXしている間は「このページは使用中だから追い出すな」というマークになります。
InnoDBでは、この一連の操作はMTR(Mini-Transaction)という単位で行われます。MTRは「数ページをまとめてアトミックに操作するための仕組み」で、B+Treeのノード分割のように複数ページを同時に触る必要がある場面で使われます。
ステップ1:ページを取得する(FIX)
上位レイヤー(B+Treeの検索など)がページを必要とするとき、buf_page_get_genを呼びます:
buf_block_t* block = buf_page_get_gen(
page_id, // 欲しいページの番号(B+Tree検索で特定済み)
page_size, // ページサイズ(通常16KB)
rw_latch, // 読み取り(S)か書き込み(X)か
guess, // ヒント(前回アクセスしたブロックのポインタ)
buf_mode, // 取得モード
mtr // このMTR(Mini-Transaction)に紐づける
);Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/include/buf0buf.h (buf_page_get_gen)
返ってくるbuf_block_tがページの管理構造体で、block->frameポインタから実際のページデータ(16KB)にアクセスできます。
ステップ2:FIX状態をマークしてロックをかける
buf_page_get_genの内部では、ページを見つけた後に2つのことをやります:
/* 1. FIXカウンタをインクリメント(「この本は貸出中」マーク) */
buf_block_fix(fix_block);
// → 内部的には page->buf_fix_count++ をしている
// → buf_fix_count > 0 のページはLRUから追い出されない
/* 2. 要求されたモードでページにロック(latch)をかける */
switch (rw_latch) {
case RW_S_LATCH: // 読み取りロック(複数スレッドが同時に読める)
rw_lock_s_lock_inline(&fix_block->lock, 0, file, line);
fix_type = MTR_MEMO_PAGE_S_FIX;
break;
case RW_X_LATCH: // 書き込みロック(1スレッドだけが書ける)
rw_lock_x_lock_inline(&fix_block->lock, 0, file, line);
fix_type = MTR_MEMO_PAGE_X_FIX;
break;
// ...
}
/* 3. MTRに「このページをこのモードでロック中」と記録 */
mtr_memo_push(mtr, fix_block, fix_type);
// → MTRコミット時にまとめて解放するために覚えておくSource: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0buf.cc (buf_page_get_gen)
ポイントは、buf_fix_count(FIX状態)とblock->lock(ラッチ)が別物だということです。FIXは「追い出し防止」、ラッチは「同時アクセス制御」。役割が違います。
ステップ3:MTRコミット時にまとめて解放(UNFIX)
MTRがコミットされると、保持していたすべてのページのFIXとロックをまとめて解放します:
static void memo_slot_release(mtr_memo_slot_t *slot) {
switch (slot->type) {
case MTR_MEMO_BUF_FIX:
case MTR_MEMO_PAGE_S_FIX:
case MTR_MEMO_PAGE_SX_FIX:
case MTR_MEMO_PAGE_X_FIX:
block = reinterpret_cast<buf_block_t *>(slot->object);
/* 1. UNFIX:buf_fix_count-- (「本を返却」) */
buf_block_unfix(block);
/* 2. ラッチ解放(他のスレッドがアクセスできるようになる) */
buf_page_release_latch(block, slot->type);
break;
}
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/mtr/mtr0mtr.cc (memo_slot_release)
MTRが複数ページを触っていた場合でも、コミット時に一括で解放されます。これにより、B+Treeのノード分割のような操作中に中途半端な状態が他のスレッドから見えることを防いでいます。
メモリの中身を覗く:Block、Page、Chunk
Buffer Poolインスタンス
まず全体像から。InnoDBはBuffer Poolを複数のインスタンスに分割しています。
innodb_buffer_pool_instances = 8 -- デフォルト(Buffer Pool ≥ 1GBの場合)
なぜ分割するかというと、ロック競合を減らすためです。1つの巨大なBuffer Poolだと、全スレッドが同じロックを奪い合います。インスタンスを分ければ、異なるインスタンスへのアクセスは完全に独立して並行処理できます。各ページはpage_idに基づいてどのインスタンスに属するかが決まります。
BlockとPage
Buffer Poolのメモリは、固定サイズのブロックに分割されています。1ブロック = 1ページ分のデータ領域(デフォルト16KB)です。
各ブロックには管理用の構造体buf_block_tが紐づいています:
struct buf_block_t {
buf_page_t page; // ページ情報(page_id、変更LSNなど)
// ※ 先頭に置くことで buf_page_t* と buf_block_t* を
// 相互にキャストできる(Cの構造体レイアウトの性質を利用)
byte* frame; // 実際のページデータ(16KB)へのポインタ
rw_lock_t lock; // ページ内容を保護する読み書きロック
BufFixCount buf_fix_count; // FIXカウンタ
// ... その他の管理情報
};Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/include/buf0buf.h (buf_block_t)
buf_page_tがbuf_block_tの先頭にあるのは設計上の工夫です。Hash Mapなどでbuf_page_t*として扱っているポインタを、必要に応じてbuf_block_t*にキャストできます。C言語ではよく使われるテクニックです。
Chunk:メモリ割り当ての単位
100GBのBuffer Poolで16KBページだと、約650万ブロックになります。これだけの数のbuf_block_t構造体(1つ数百バイト)のメモリも馬鹿になりません。
InnoDBはこれを効率的に管理するため、Chunkという単位でメモリを確保します(デフォルト128MB)。1つのChunkの中身はこうなっています:
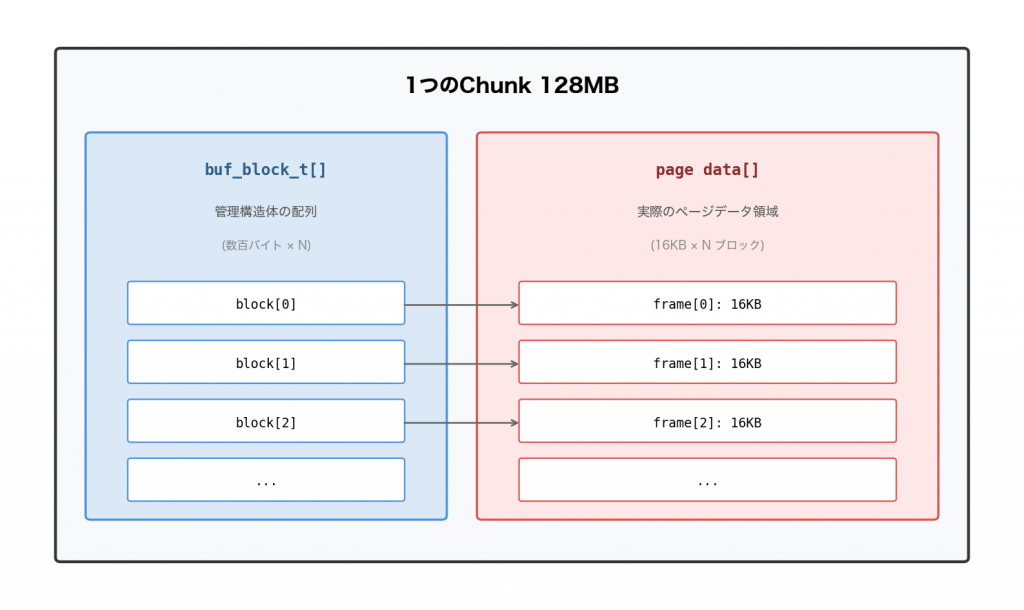
管理構造体とページデータを1つの連続メモリ領域にまとめて確保しています。起動時にbuf_chunk_initがmmapでメモリを確保しますが、Linuxの仮想メモリの仕組みにより、実際の物理メモリは使われたページから徐々に消費されていきます。
なお、buf_block_tのサイズが16KBの約数とは限らないため、ページデータ領域の先頭にわずかなフラグメント(使われない隙間)が生じることがあります。これがinnodb_buffer_pool_sizeで設定した値より実際のメモリ使用量がやや大きくなる理由の一つです。
Chunkが導入されたのはMySQL 5.7からで、目的はオンラインリサイズへの対応です。Chunk単位で追加・削除できるので、サーバーを止めずにBuffer Poolのサイズを変更できます。
4つのデータ構造:Hash Map、LRU List、Free List、Flush List
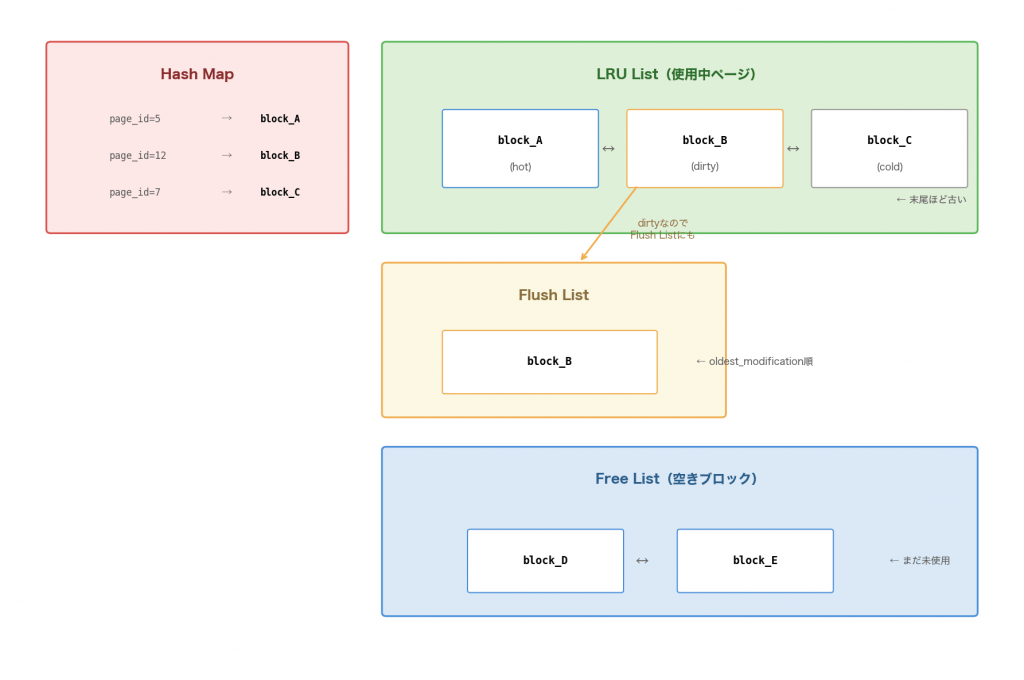
Buffer Pool内のブロックは、4つのデータ構造で管理されています。それぞれ役割が違います。
Hash Map:「このページはメモリにある?」を高速に調べる
page_id → buf_block_t* のハッシュテーブルbuf_page_get_genが呼ばれるたびに、まずHash Mapを引いて「そのページがすでにBuffer Poolにあるか」を調べます。最も頻繁にアクセスされるデータ構造です。衝突解決にはチェイン法(リンクリスト)を使っています。
Free List:空きブロックのリスト
まだページが読み込まれていない、使える空きブロックの一覧起動直後はすべてのブロックがFree Listにいます。ページが読み込まれるとFree Listから取り出され、LRU Listに移動します。
LRU List:使用中ブロックの管理(置換アルゴリズム)
最近アクセスされたページほど先頭に近い位置にいるリストメモリが足りなくなったとき、LRU Listの末尾から古いページを追い出します。詳細は次のセクションで解説します。
Flush List:ダーティページの管理
変更されたがまだディスクに書き戻されていないページのリスト
oldest_modification(最初に変更されたLSN)の順に並んでいるダーティページ(変更済みページ)はLRU Listにも、Flush Listにも同時に存在します。Flush Listはチェックポイント位置の決定とフラッシュ対象の選定に使われます。
各ブロックの所属ルール
すべてのブロックはFree List(未使用) OR LRU List(使用中)どちらかに必ず属する。
さらに、LRU List上のブロックのうち、変更されたものは Flush Listにも載る
Hash MapにはLRU List上のすべてのブロックが登録されている
全体像を図にするとこうです:
ページを取りに行く流れ
buf_page_get_genはBuffer Poolの中心的な関数です。呼ばれたときに何が起きるか、ケースごとに見ていきましょう。
ケース1:Buffer Poolヒット(最も一般的)
欲しいページがすでにメモリ上にある場合。これが一番多いケースで、よくチューニングされたBuffer Poolなら99%以上がここに該当します。
buf_page_get_gen(page_id=5, ...)
│
├─ 1. Hash Mapで page_id=5 を検索
│ → 見つかった! block_A が返る
│
├─ 2. buf_block_fix(block_A) // FIXカウンタ++
│
├─ 3. rw_lock_s_lock(block_A->lock) // ラッチ取得
│
├─ 4. buf_page_make_young_if_needed(block_A)
│ // LRU List上の位置を更新するか判定(後述)
│
└─ 5. return block_A // 呼び出し元にページを返すヒット率はSHOW ENGINE INNODB STATUSで確認できます:
SHOW ENGINE INNODB STATUS\G
-- BUFFER POOL AND MEMORY セクションに以下が表示される:
-- Buffer pool hit rate 999 / 1000
-- ↑ 1000回中999回がヒット = 99.9%ケース2:Buffer Poolミス(ページがメモリにない)
Hash Mapで見つからなかった場合、ディスクから読み込む必要があります。そのためにはまず空きブロックを確保しなければなりません。
buf_page_get_gen(page_id=99, ...)
│
├─ 1. Hash Mapで page_id=99 を検索
│ → 見つからない!
│
├─ 2. buf_LRU_get_free_block() で空きブロックを確保
│ (詳細は下で解説)
│
├─ 3. buf_page_init() でブロックを初期化
│ → page_id=99 をセット
│ → Hash Map に登録
│ → LRU List に追加
│
├─ 4. ディスクI/Oでページデータを block->frame に読み込み
│ (読み込み中は io_fix = BUF_IO_READ をセット)
│ (block->lock を X Lock で保持 → 他スレッドは待つ)
│
└─ 5. FIX + ラッチ取得して return空きブロックの確保:buf_LRU_get_free_block
ここがBuffer Poolの中でも複雑な部分です。3段階のフォールバックがあります:
buf_LRU_get_free_block()
│
│ ★ 第1段階:Free Listから取る
├─ buf_LRU_get_free_only()
│ → Free Listにブロックがあれば、取り出して返す
│ → 起動直後はここで済む。運用が進むとFree Listは空になりがち
│
│ ★ 第2段階:LRU Listの末尾から追い出す
├─ buf_LRU_scan_and_free_block()
│ │
│ │ LRU Listの末尾から innodb_lru_scan_depth 個を走査
│ │ 追い出せるページの条件(3つすべて満たす必要あり):
│ │ ✓ ダーティページではない(変更がディスクに書き戻し済み)
│ │ ✓ buf_fix_count == 0(誰も使っていない)
│ │ ✓ io_fix == BUF_IO_NONE(I/O中でない)
│ │
│ └─ 見つかったら buf_LRU_free_page() で:
│ → LRU Listから削除
│ → Hash Mapから削除
│ → Free Listに追加
│ → そのブロックを返す
│
│ ★ 第3段階:それでもダメなら強制フラッシュ
└─ buf_flush_single_page_from_LRU()
│
│ LRU末尾のダーティページを1つ同期的にフラッシュ
│ (ディスクに書き戻してクリーンにする)
│ → クリーンになったので追い出し可能に
│
└─ ※ これはユーザースレッドが同期的に待つので遅い
理想的にはここに来ないようにチューニングすべき第3段階のbuf_flush_single_page_from_LRUに頻繁に到達するようなら、ダーティページが多すぎるサインです。Buffer Poolサイズの拡大か、フラッシュ設定の見直しが必要です。
先読み(Read-Ahead)
ディスクI/Oが発生したとき、InnoDBは「ついでに近くのページも読んでおこう」と判断することがあります。ディスク(特にHDD)は連続読み取りが得意なので、これが効くとI/O回数を大幅に減らせます。
2種類の先読みがあります:
- リニア先読み(Sequential Read-Ahead)
- 「同じExtent内のページが連続的にアクセスされている」
→ 次のExtentのページをまとめて読み込む - 設定: innodb_read_ahead_threshold(デフォルト56)
→ Extent内の56ページ以上が連続アクセスされたら発動
- 「同じExtent内のページが連続的にアクセスされている」
- ランダム先読み(Random Read-Ahead)
- 「同じExtent内の多くのページが最近アクセスされている」
→ そのExtentの残りのページも読み込む - 設定: innodb_random_read_ahead(デフォルトOFF)
→ テーブルスキャンが多いワークロードで有効な場合がある
- 「同じExtent内の多くのページが最近アクセスされている」
※ Extent = 64ページ(= 1MB)の連続領域。InnoDBのスペース管理の基本単位です。
LRUの工夫:なぜ単純なLRUだとダメなのか
単純なLRUの問題
教科書的なLRUは「アクセスされたページをリストの先頭に移動する」というシンプルなルールです。最近使われたものほど先頭に近く、長く使われていないものが末尾に溜まって追い出される。直感的でわかりやすいですよね。
でも、これには致命的な弱点があります。テーブルフルスキャンです。
-- こういうクエリを1回実行しただけで...
SELECT * FROM huge_table; -- 100万ページのテーブル
-- 何が起きるか:
-- 1. huge_tableの全ページが次々とBuffer Poolに読み込まれる
-- 2. 読み込まれるたびにLRU先頭に移動する
-- 3. 今まで頻繁に使われていたホットなページが末尾に押し出される
-- 4. ホットなページが追い出される
-- 5. スキャン完了後、huge_tableのページはもう二度と使われない
-- 6. でもBuffer Poolの中身はhuge_tableのページで埋まっている
-- → しばらくの間、ヒット率がガタ落ちする(Buffer Pool汚染)これは「1回しかアクセスされないページ」と「何度もアクセスされるページ」を区別できないことが原因です。
InnoDBの解決策:New/Old Sublist
InnoDBはLRU Listを2つの領域に分割しています:
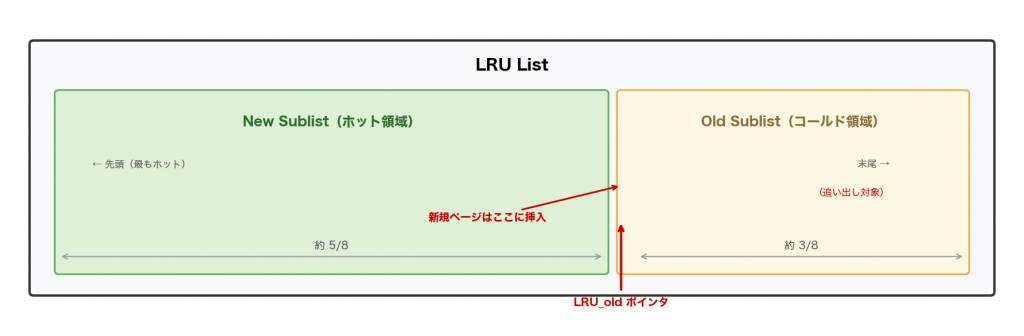
新しく読み込まれたページは、先頭ではなくOld Sublistの先頭(= LRU_oldの位置)に挿入されます:
// buf_LRU_add_block の動作
void buf_LRU_add_block(buf_page_t* bpage, bool old) {
if (old) {
// LRU_old の位置(3/8地点)に挿入
// → New Sublistのホットなページを押し出さない!
} else {
// LRU Listの先頭に挿入
}
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0lru.cc (buf_LRU_add_block)
この分割が有効になるのは、LRU Listの長さがBUF_LRU_OLD_MIN_LEN(512ブロック)を超えてからです。それ以下の小さなBuffer Poolでは分割の意味が薄いためです。
Old SublistからNew Sublistへの昇格
Old Sublistに入ったページが「本当に必要なページ」なら、New Sublistに昇格させたい。この判定を行うのがbuf_page_make_young_if_neededです:
// buf_page_get_gen の中で毎回呼ばれる
buf_page_make_young_if_needed(bpage);Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0buf.cc (buf_page_make_young_if_needed)
昇格の条件は、ページがOld/Newどちらにいるかで異なります:
- ページが Old Sublist にいる場合:
- 最初のアクセスから innodb_old_blocks_time 以上経過していること(デフォルト: 1000ミリ秒)
→ フルスキャンで一瞬だけ触られたページは昇格しない
→ 1秒以上経ってからまたアクセスされた = 本当に必要
→ New Sublistの先頭に移動
- 最初のアクセスから innodb_old_blocks_time 以上経過していること(デフォルト: 1000ミリ秒)
- ページが New Sublist にいる場合:
- 先頭から約 1/6 より後ろにいること
→ すでに先頭付近にいるホットなページは移動しない
→ 毎回先頭に移動すると、リスト操作のロック競合が増える
→ 「十分ホットならわざわざ動かさない」という最適化
- 先頭から約 1/6 より後ろにいること
フルスキャン耐性の仕組み
これで先ほどのフルスキャン問題がどう解決されるか見てみましょう:
SELECT * FROM huge_table; を実行
1. huge_tableのページが次々読み込まれる
2. すべて Old Sublist の先頭(LRU_old位置)に挿入される
3. スキャンは高速に進むので、各ページは一瞬で読まれて次に進む
4. innodb_old_blocks_time(1秒)以内に再アクセスされない
5. → Old Sublistに留まったまま、末尾に押し出されて追い出される
結果:
New Sublistのホットなページは一切影響を受けない!
汚染されるのは Old Sublist(全体の約3/8)だけLRU_oldポインタの維持
ページの挿入・削除のたびに、Old Sublistが全体の約3/8になるようLRU_oldポインタを調整する必要があります:
// ページの挿入・削除のたびに呼ばれる
buf_LRU_old_adjust_len() {
// Old Sublistの実際の長さと、理想の長さ(全体の3/8)を比較
// ずれていたらLRU_oldポインタを前後に移動
// ただし BUF_LRU_OLD_TOLERANCE(20) の許容範囲内なら何もしない
// → 毎回厳密に調整すると、ポインタ移動のコストが高くつくため
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0lru.cc (buf_LRU_old_adjust_len)
BUF_LRU_OLD_TOLERANCE = 20という許容範囲を設けることで、「だいたい3/8」を維持しつつ、調整の頻度を抑えています。厳密さよりパフォーマンスを優先する、実用的な設計です。
ダーティページとフラッシュ
ダーティページはどうやって生まれるか
ページを変更するとき、InnoDBは以下の流れで処理します:
1. buf_page_get_gen(page_id, RW_X_LATCH, mtr)
→ ページを X Lock(排他ロック)で取得
2. ページの内容をメモリ上で直接変更
→ block->frame の中身を書き換える
3. 対応する Redo Log を MTR のローカルバッファに書く
4. MTR コミット時:
→ Redo Log をグローバルな Log Buffer にコピー
→ buf_flush_note_modification() でページを Flush List に追加buf_flush_note_modificationでは、ページに2つのLSN(Log Sequence Number)を記録します:
buf_flush_note_modification(block, start_lsn, end_lsn) {
block->page.oldest_modification = start_lsn;
// ↑ このページが最初に変更されたときのLSN
// すでにセット済みなら上書きしない(最初の変更時点を保持)
block->page.newest_modification = end_lsn;
// ↑ このページが最後に変更されたときのLSN
// 変更のたびに更新される
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/include/buf0flu.h (buf_flush_note_modification)
oldest_modificationがチェックポイントの進行に直結します。Flush List上のすべてのダーティページの中で最小のoldest_modificationが、チェックポイントを進められる限界位置になります。つまり、古いダーティページがいつまでも残っていると、チェックポイントが進まず、Redoログの空き領域が枯渇します。
いつフラッシュするか:2つの圧力
フラッシュのタイミングを決めるのは、2つの要因です:
- 圧力1:ダーティページの総数
- Buffer Pool内のダーティページが多すぎると、LRUで追い出したいページがダーティばかりになり空きブロックの確保が遅くなる
→ LRU List の末尾付近を優先的にフラッシュしたい
- Buffer Pool内のダーティページが多すぎると、LRUで追い出したいページがダーティばかりになり空きブロックの確保が遅くなる
- 圧力2:アクティブRedoの総量
- チェックポイントLSN以降のRedoログの量が多すぎると、Redoログの空き領域が足りなくなる
→ oldest_modification が小さいページ(= Flush List の末尾)を優先的にフラッシュしたい
- チェックポイントLSN以降のRedoログの量が多すぎると、Redoログの空き領域が足りなくなる
この2つの圧力は、フラッシュ対象の選び方が異なります。ダーティページ数はLRU末尾を、アクティブRedo量はFlush List末尾を狙います。だからLRU ListとFlush Listの両方が必要なのです。
3つのフラッシュモード
| モード | トリガー | 影響 |
|---|---|---|
| Single Flush | 空きブロックが全く取れない | ユーザースレッドが同期的に1ページだけフラッシュ。遅い。避けるべき |
| Sync Flush | Redoログの空きが危機的 | 大量のページを一気にフラッシュ。ユーザーリクエストに影響大 |
| Batch Flush(理想) | バックグラウンドで常時稼働 | 定期的に適量をフラッシュ。これが主役 |
Single FlushとSync Flushはどちらも緊急モードです。理想的にはBatch Flushだけで回るようにチューニングすべきです。
Batch Flushの仕組み
Batch Flushはpage coordinatorスレッド(1つ)とpage cleanerスレッド(複数、Buffer Poolインスタンス数に対応)で構成されます。
page coordinator(定期的に起動)
│
├─ 1. page_cleaner_flush_pages_recommendation() で
│ 今回フラッシュすべきページ数 n_pages を計算
│
├─ 2. n_pages を各 page cleaner に均等に配分
│
├─ 3. 全 page cleaner を起こして、自分も1インスタンス分を担当
│
└─ 4. 全員の完了を待って、次のラウンドへn_pagesの計算式がBatch Flushの核心です:
n_pages = (innodb_io_capacity * max(pct_for_dirty, pct_for_lsn) / 100
+ avg_page_rate
+ pages_for_lsn
) / 3;
// 上限チェック
if (n_pages > srv_max_io_capacity) {
n_pages = srv_max_io_capacity;
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0flu.cc
(元記事に出てくるコードはおそらく、af_get_pct_for_dirty, af_get_pct_for_lsn, buf_flush_page_coordinator_thread 内のロジックを簡略化した擬似コードのようです。)
4つの要素を分解します:
| 要素 | 種類 | 説明 |
|---|---|---|
| pct_for_dirty | 静的 | ダーティページ率から算出。lwm以下なら0、pct以上なら100、間は線形増加 |
| pct_for_lsn | 静的 | アクティブRedo量から算出。増加が加速する(危険度が高いほど急) |
| avg_page_rate | 動的 | 前回からの期間でのダーティページ増加速度 |
| pages_for_lsn | 動的 | Redo増加速度をFlush List上のページ数に投影した値 |
静的な水位(①②)と動的な変化速度(③④)の両方を見ているのがポイントです。水位が低くても急速に増えていれば多めにフラッシュし、水位が高くても増加が止まっていれば控えめにする、というバランスです。
各page cleanerの動作
各page cleanerは担当するBuffer Poolインスタンスに対して、LRU ListとFlush Listの両方からフラッシュします:
page cleaner の1ラウンド
│
├─ 1. LRU List からフラッシュ
│ Free Listのブロック数 < innodb_lru_scan_depth なら実行
│ LRU末尾を走査:
│ クリーンなページ → buf_LRU_free_page() で直接解放
│ ダーティページ → buf_flush_page_and_try_neighbors()
│
└─ 2. Flush List からフラッシュ
oldest_modification が小さい順に走査
→ buf_flush_page_and_try_neighbors()buf_flush_page_and_try_neighborsは名前の通り、対象ページだけでなく近隣のダーティページもまとめてフラッシュしようとします:
buf_flush_page_and_try_neighbors(page_id, ...) {
// page_id の近くにあるダーティページも一緒にフラッシュ
// → ディスクの連続書き込み性能を活かすため
// → innodb_flush_neighbors で制御
// 0: 無効(SSDならこれが推奨)
// 1: 同じExtent内の連続ダーティページ
// 2: 同じExtent内のすべてのダーティページ
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0flu.cc (buf_flush_page_and_try_neighbors)
HDDでは連続書き込みが圧倒的に速いのでこの最適化が効きますが、SSDではランダム書き込みも速いので無効(0)にするのが一般的です。
フラッシュ完了後の後処理
すべてのフラッシュは最終的にbuf_flush_write_block_lowでディスクに書き込まれます。Single Flush以外は非同期I/Oで、完了時にI/Oスレッドがbuf_page_io_completeをコールバックします:
buf_page_io_complete(page) {
// 1. io_fix を BUF_IO_NONE に戻す
// 2. page lock を解放
// 3. Flush List から削除(もうダーティじゃない)
// 4. 必要に応じて LRU List から削除 → Free List へ
}Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/buf/buf0buf.cc (buf_page_io_complete)
ロックの話:みんなが同時にアクセスしても壊れない仕組み
Buffer Poolには大量のスレッドが同時にアクセスします。ユーザースレッド、page cleanerスレッド、I/Oスレッド…。これらが同じデータ構造を壊さずに使えるのは、4種類のロックが守っているからです。
4種類のロック
粒度が大きい順に:
| ロック | 保護対象 | ポイント |
|---|---|---|
| Hash Map Lock | page_id→blockのハッシュテーブル | 16パーティションに分割。異なるパーティションは完全並行 |
| List Mutex | LRU/Free/Flush Listの構造 | 各リストに独立Mutex。ノード追加・削除の瞬間だけ保持 |
| Block Mutex | buf_block_tの状態情報(io_fix, buf_fix_countなど) | ページ内容は触らない。「追い出せるか?」の判定に使う |
| Page Frame Lock | block->frame(実際の16KBデータ) | S Lock(読み取り)/ X Lock(書き込み)/ SX Lock(I/O書き込み中) |
Block MutexとPage Frame Lockが分かれているのは重要な設計判断です。「このページは追い出せるか?」を確認するだけならio_fixとbuf_fix_countを見ればよく、ページの中身を読む必要はありません。軽いBlock Mutexで済む操作に、重いPage Frame Lockを使わなくて済みます。
デッドロック回避:Latch Order
複数のロックを同時に持つ必要がある場面では、デッドロックのリスクがあります。InnoDBはこれをロック取得順序の固定で回避しています:
enum latch_level_t {
// ↓ 必ずこの順番(下から上)で取得する
SYNC_BUF_FLUSH_LIST, // Flush List Mutex (最初に取る)
SYNC_BUF_FREE_LIST, // Free List Mutex
SYNC_BUF_BLOCK, // Block Mutex
SYNC_BUF_PAGE_HASH, // Hash Map Lock
SYNC_BUF_LRU_LIST, // LRU List Mutex (最後に取る)
};Source: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/include/sync0types.h
ルールは単純です:番号が小さいロックを先に取る。すべてのスレッドがこの順序を守れば、循環待ちは発生しません。
例外的に順序を守れない場合は、いったんロックを解放してから取り直します。たとえばFlush Listを走査中にBlock Mutexが必要になった場合、Flush List Mutexの方がレベルが低いので、先にFlush List Mutexを解放してからBlock Mutexを取得します。
実際のシナリオで見るロックの流れ
「page_id=99がBuffer Poolにない」場合の全ロック取得・解放を追ってみましょう:
ステップ 保持中のロック
─────────────────────────────────────────────
1. Hash Map Lock (S) 取得 [Hash(S)]
page_id=99 を検索 → ない
Hash Map Lock 解放 []
2. LRU List Mutex 取得 [LRU]
Free List Mutex 取得 [LRU, Free]
Free Listから空きブロック取得
Free List Mutex 解放 [LRU]
3. Hash Map Lock (X) 取得 [LRU, Hash(X)]
Block Mutex 取得 [LRU, Hash(X), Block]
ブロックを初期化、Hash Mapに登録
LRU Listに追加
Block Mutex 解放 [LRU, Hash(X)]
Hash Map Lock 解放 [LRU]
LRU List Mutex 解放 []
4. Page Frame Lock (X) 取得 [PageFrame(X)]
io_fix = BUF_IO_READ をセット
ディスクI/O実行(この間は他のロックなし)
io_fix = BUF_IO_NONE に戻す
Page Frame Lock 解放 []
5. Block Mutex 取得 [Block]
buf_fix_count++
Block Mutex 解放 []
Page Frame Lock (S or X) 取得 [PageFrame]
→ 呼び出し元に返す
注目すべきポイント:
- 各ロックの保持範囲が最小限に絞られている
- ディスクI/O中はPage Frame Lock以外のロックを持っていない(他のスレッドをブロックしない)
- ロック取得順序が常にLatch Orderに従っている(LRU → Hash → Block の順)
まとめ
この記事では、InnoDB Buffer Poolの内部実装を追いかけました。振り返ると:
| テーマ | キーポイント |
|---|---|
| 基本インターフェース | FIX-UNFIX。MTR単位でページを借りて返す |
| メモリ構成 | Chunk → Block → Page。4つのデータ構造で管理 |
| ページ取得 | Hash Mapでヒット判定 → ミスならFree List → LRU追い出し → 最終手段で同期フラッシュ |
| LRU | New/Old Sublist分割でスキャン耐性を確保 |
| フラッシュ | ダーティページ率とアクティブRedo量の2軸で判断。Batch Flushが主役 |
| ロック | 4種類のロックを粒度別に使い分け。Latch Orderでデッドロック回避 |
Buffer Poolの設計思想は一貫しています:ディスクI/Oを最小化しつつ、高い同時実行性能を維持する。そのために、LRUの分割、非同期フラッシュ、パーティションロック、ロック粒度の細分化といった工夫が積み重ねられています。
数十年の歴史を持つ工業製品だけあって、細部には最適化が詰まっていますが、根底にある考え方はシンプルです。この記事が、Buffer Poolの「なぜそうなっているか」を理解する助けになれば幸いです。
参考
- An In-Depth Analysis of Buffer Pool in InnoDB – Kang Wang (ApsaraDB)
- MySQL 8.0 Source Code
- InnoDB Buffer Pool – MySQL公式ドキュメント

コメント