はじめに
この記事では、Oracle DatabaseのBuffer Cacheの内部構造を解説します。
InnoDB Buffer Pool編、PostgreSQL Shared Buffers編に続く第3弾です。Oracleはクローズドソースなのでソースコードは読めませんが、公式ドキュメント、X$BH(内部ビュー)、V$BH(動的パフォーマンスビュー)、そしてOracle Internals系の文献をもとに、InnoDB・PostgreSQLと同等の深さで解説します。
この記事で扱う内容:
- Pin/Unpinの仕組み
- メモリ構成(Buffer Header、Hash Chain、LRU List、Checkpoint Queue)
- Touch Countアルゴリズム(Hot/Cold領域の分割)
- フルテーブルスキャン耐性の仕組み
- DBWnによるダーティページの書き戻し
- ラッチとロックによる同時実行制御
対象バージョンはOracle 19c〜23aiです。
そもそもBuffer Cacheって何?
InnoDB・PostgreSQLと同じ役割です。ディスク上のデータブロックをメモリにキャッシュして、物理I/Oを最小化する仕組みです。OracleではSGA(System Global Area)の一部として確保されます。
-- Buffer Cacheのサイズ設定
ALTER SYSTEM SET db_cache_size = 4G;
-- または自動メモリ管理(AMM)に任せる
ALTER SYSTEM SET memory_target = 16G;Oracleのブロックサイズはデフォルト8KB(PostgreSQLと同じ、InnoDBの16KBの半分)です。
3つのプール
OracleのBuffer Cacheは用途別に分けられます:
- Default Pool(デフォルト)
- 通常のブロックがキャッシュされる場所
- ほとんどのブロックはここに入る
- Keep Pool(オプション)
- 頻繁にアクセスされるテーブルを常駐させたい場合に使う
- ALTER TABLE t STORAGE (BUFFER_POOL KEEP);
- Recycle Pool(オプション)
- アクセス頻度が低い大きなテーブル用
- キャッシュを長く占有させたくない場合に使う
Keep/Recycle Poolは明示的にテーブルに割り当てる必要があります。InnoDBやPostgreSQLにはこの概念はありません。
Pin/Unpin:ブロックの借り方・返し方
OracleでもInnoDB・PostgreSQLと同じく、ブロックを使用中はPinして追い出しを防ぎます。
ブロック取得の流れ
ユーザープロセスがブロックを必要とするとき、内部的には以下の流れで処理されます:
ユーザープロセスがブロックを要求
│
├─ 1. Buffer Tagを計算(data file番号 + block番号)
│
├─ 2. Hash関数でBucket番号を算出
│
├─ 3. Cache Buffer Chains ラッチを取得
│ → Hash Chainを辿ってBuffer Headerを検索
│
├─ ヒット:
│ ├─ Buffer HeaderのPin countをインクリメント
│ ├─ Touch countをインクリメント(後述)
│ └─ ブロックの内容にアクセス
│
└─ ミス:
├─ Free Listまたは LRU Listから空きバッファを確保
├─ ディスクからブロックを読み込み
├─ Hash Chainに登録
└─ PinしてアクセスBuffer Header
各バッファにはBuffer Headerという管理構造体が紐づいています。X$BH内部ビューで確認できます:
-- Buffer Headerの主要フィールド(X$BH)
SELECT
HLADDR, -- Hash Chain Latchのアドレス
FILE#, -- データファイル番号
DBABLK, -- ブロック番号
CLASS#, -- ブロックの種類(data, undo, headerなど)
STATE, -- 状態(0=FREE, 1=XCUR, 2=SCUR, 3=CR, ...)
TCH, -- Touch Count(アクセス回数)
TIM, -- 最終アクセス時刻
BA, -- バッファのメモリアドレス
DIRTY_QUEUE, -- Checkpoint Queueに載っているか
NXT_HASH, -- Hash Chainの次のBuffer Header
PRV_HASH -- Hash Chainの前のBuffer Header
FROM X$BH
WHERE ROWNUM <= 10;InnoDBのbuf_block_t、PostgreSQLのBufferDescに相当しますが、Oracleの特徴はBuffer HeaderがSGA内のShared Poolに格納される点です(バッファデータ自体はBuffer Cache内)。
InnoDBとの比較
| InnoDB | PostgreSQL | Oracle | |
|---|---|---|---|
| 取得 | buf_page_get_gen | ReadBuffer | 内部関数(非公開) |
| 追い出し防止 | buf_fix_count++ | refcount++ | Pin count++ |
| 管理構造体 | buf_block_t | BufferDesc | Buffer Header(X$BH) |
| 格納場所 | Buffer Pool内(Chunk) | 共有メモリ | Shared Pool内 |
| ブロックサイズ | 16KB | 8KB | 8KB(デフォルト) |
メモリの中身を覗く:Hash Chain、LRU List、Checkpoint Queue
Hash Chain:ブロックの検索
InnoDB・PostgreSQLと同じく、Oracleもハッシュテーブルでブロックを検索します。OracleではHash BucketとHash Chainと呼びます。
Hash Bucket 0 → [BH: file#=1, blk#=100] → [BH: file#=3, blk#=200] → NULL
Hash Bucket 1 → [BH: file#=2, blk#=50] → NULL
Hash Bucket 2 → [BH: file#=1, blk#=300] → [BH: file#=5, blk#=10] → NULL
...
※ BH = Buffer Header
※ 同じBucketに複数のBuffer Headerがチェインされる(衝突解決)各Hash ChainはCache Buffer Chains ラッチで保護されています。ラッチの数はバッファ数に応じて自動的に決まり、1つのラッチが複数のHash Chainを保護します。
-- Cache Buffer Chains ラッチの競合を確認
SELECT name, gets, misses, sleeps
FROM V$LATCH
WHERE name = 'cache buffer chains';このラッチの競合(latch: cache buffer chains待機イベント)は、Oracleのパフォーマンスチューニングで最も頻繁に遭遇する問題の一つです。同じブロックに大量のセッションが同時アクセスする「ホットブロック」問題が原因であることが多いです。
LRU List:Hot領域とCold領域
OracleのLRU Listは、InnoDBのNew/Old Sublistと似た構造で、Hot領域とCold領域に分割されています:
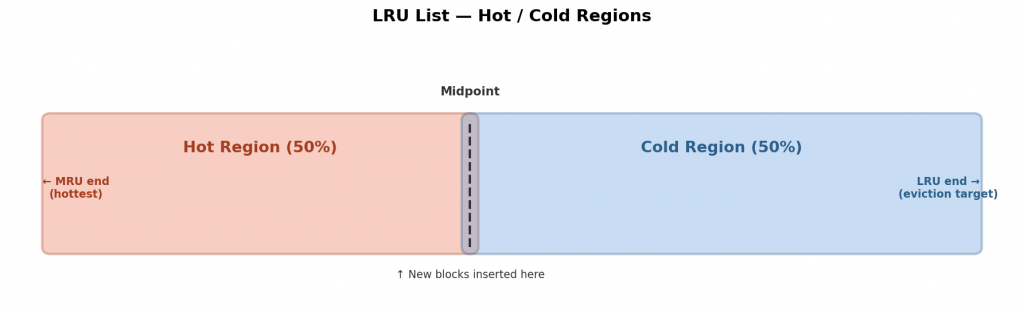
InnoDBのNew/Old Sublistとの違い:
- InnoDBは5/8と3/8の分割、Oracleはデフォルト50/50
- InnoDBは
innodb_old_blocks_timeで昇格を制御、OracleはTouch Countで制御(後述)
Checkpoint Queue(CKPT-Q)
InnoDBのFlush Listに相当するのがCheckpoint Queueです。ダーティバッファが変更された順(RBA = Redo Block Address順)に並んでいます。
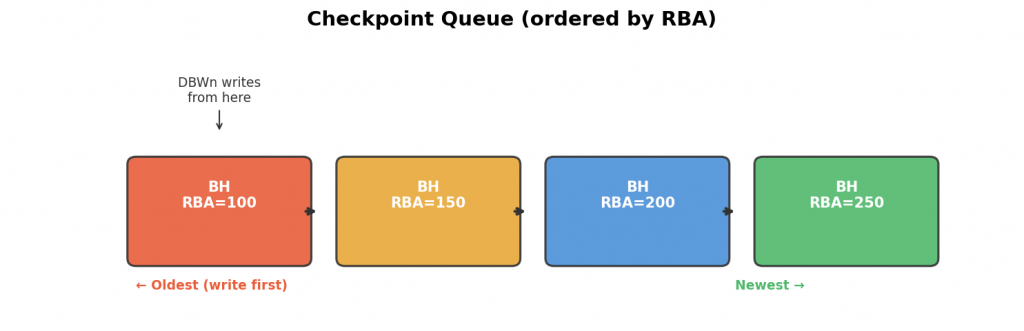
InnoDBのFlush Listがoldest_modification(LSN)順なのと同じ考え方です。チェックポイントを進めるには、Checkpoint Queueの先頭(最も古いダーティバッファ)をディスクに書き出す必要があります。
4つのデータ構造の比較
| 役割 | InnoDB | PostgreSQL | Oracle |
|---|---|---|---|
| ブロック検索 | Hash Map | buf_table | Hash Bucket + Chain |
| 使用中管理 | LRU List | なし(配列走査) | LRU List |
| 空きブロック | Free List | Free List | Free List(LRU末尾) |
| ダーティ管理 | Flush List | なし | Checkpoint Queue |
| スキャン耐性 | New/Old Sublist | Ring Buffer | Hot/Cold + Touch Count |
Touch Count:ブロックの「人気度」を測る
OracleのLRU管理の核心は**Touch Count(TCH)**です。PostgreSQLのusage_countに近い概念ですが、より洗練されています。
Touch Countの基本
バッファがアクセスされるたびに、Buffer HeaderのTouch Count(X$BH.TCH)がインクリメントされます。ただし、短時間に何度もアクセスされた場合は1回としかカウントしません(3秒間隔のウィンドウがあると言われています)。
-- Touch Countの分布を確認
SELECT tch, COUNT(*) AS buffers
FROM X$BH
WHERE state != 0 -- FREE以外
GROUP BY tch
ORDER BY tch;
-- 結果例:
-- TCH BUFFERS
-- --- -------
-- 0 15000 ← 一度もアクセスされていない or 最近読み込まれたばかり
-- 1 8000
-- 2 5000
-- 3 3000
-- 10 1000 ← ホットなブロック
-- 50 200 ← 非常にホットなブロック
Hot領域への昇格
新しく読み込まれたブロックは、LRU ListのCold領域の中間地点(Midpoint)に挿入されます。その後、Touch Countが一定の閾値を超えると、Hot領域に昇格します。
1. ブロックがディスクから読み込まれる
→ Cold領域のMidpointに挿入(TCH = 0)
2. アクセスされるたびに TCH++
3. TCH が閾値を超える
→ Hot領域のMRU端に移動
4. Hot領域内でもアクセスされるたびにMRU端に近づく
5. アクセスされなくなると徐々にLRU端に向かって移動
→ 最終的にCold領域に落ちる
→ さらにアクセスされなければ追い出し対象にInnoDBとの比較
InnoDBのNew/Old Sublist方式との違いが面白いです:
- InnoDB: 時間ベースの昇格
- Old Sublistに入ったページが昇格するにはinnodb_old_blocks_time(デフォルト1秒)経過後に再アクセスされる必要がある
- 「1秒以内の再アクセスは無視」という時間フィルタ
- Oracle: 回数ベースの昇格(Touch Count)
- アクセス回数(TCH)が閾値を超えたら昇格
- 3秒以内の連続アクセスは1回とカウント
- 「何回アクセスされたか」という頻度フィルタ
- PostgreSQL: 減衰ベース(usage_count)
- アクセスでusage_count++(上限5)
- Clock Sweepが通過するたびに usage_count–
- 「最近どれだけアクセスされたか」の減衰カウンタ
3つのDBMSとも「頻繁にアクセスされるブロックを優遇する」という目標は同じですが、アプローチが異なります。
フルテーブルスキャン耐性
Oracleのフルテーブルスキャン(FTS)対策は、バージョンによって進化してきました:
Oracle 9.2以前:
FTSのブロックはLRU端に挿入(すぐ追い出される)
→ 小さなウィンドウ内でのみキャッシュ
Oracle 9.2以降:
FTSのブロックもMidpointに挿入
ただし、テーブルサイズによって挙動が変わる:
テーブルサイズ < small_table_threshold(Buffer Cacheの2%)
→ 通常通りキャッシュ(小さいテーブルは全部載せてOK)
テーブルサイズ > Buffer Cacheの一定割合
→ Direct Path Read(Buffer Cacheをバイパス)
PGAに直接読み込む
→ Buffer Cacheへの影響はゼロ
Oracle 11g以降のオプティマイザは、大きなテーブルのFTSに対してDirect Path Readを選択することが多くなりました。これはBuffer Cacheを完全にバイパスしてPGA(プロセス専用メモリ)に直接読み込む方式です。
-- Direct Path Readが使われているか確認
SELECT name, value
FROM V$SYSSTAT
WHERE name IN ('physical reads', 'physical reads direct');PostgreSQLのRing Bufferが「小さなリングで使い回す」アプローチなのに対し、Oracleは「そもそもBuffer Cacheを通さない」というより大胆なアプローチです。
DBWnによるダーティページの書き戻し
InnoDBのpage cleaner、PostgreSQLのBGWriterに相当するのが、Oracleの**DBWn(Database Writer)**プロセスです。
DBWnの基本
DBWnはバックグラウンドプロセスで、ダーティバッファをデータファイルに書き戻します。複数のDBWnプロセスを起動できます(DB_WRITER_PROCESSESパラメータ)。
-- DBWnプロセス数の確認
SHOW PARAMETER db_writer_processes;
-- デフォルト: 1(CPUコア数に応じて自動調整されることもある)DBWnが起動するタイミング
DBWnは以下の条件で書き出しを行います:
- サーバープロセスがFreeバッファを見つけられない、LRU Listを走査してもクリーンなバッファが見つからない
→ DBWnにシグナルを送って書き出しを要求
→ InnoDBのSingle Flushに相当する状況 - Checkpoint Queueが長くなりすぎたチェックポイントを進めるために、古いダーティバッファを書き出す必要がある
→ InnoDBのSync Flushに相当 - 定期的なタイムアウト(3秒間隔)
→ InnoDBのBatch Flush、PostgreSQLのBGWriterに相当 - テーブルスペースのオフライン/読み取り専用化
- DROP TABLE / TRUNCATE TABLE
- ALTER TABLESPACE BEGIN BACKUP │
Checkpoint Queue からの書き出し
DBWnがCheckpoint Queueから書き出すとき、キューの先頭(最も古いダーティバッファ)から順に処理します:
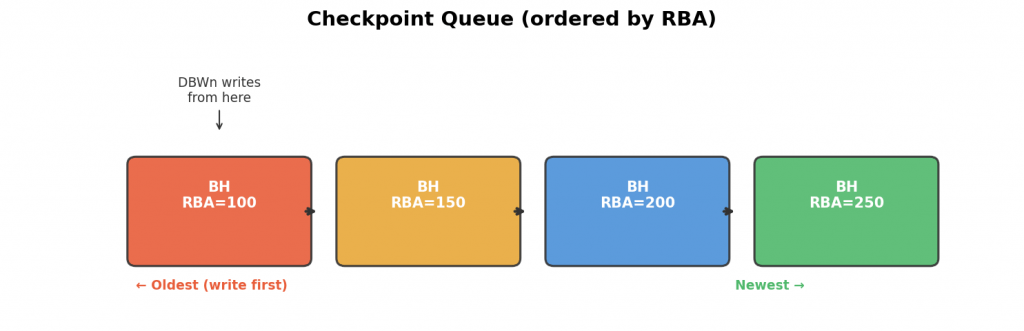
これはInnoDBのFlush Listからのフラッシュと同じ考え方です。Checkpoint Queueの先頭が進むことで、REDOログの再利用可能な領域が増えます。
LRU Listからの書き出し
サーバープロセスがFreeバッファを必要としているとき、DBWnはLRU ListのCold端からダーティバッファを書き出します:
LRU List
Hot端 ←────────────────→ Cold端
[...] [...] [...] [dirty] [dirty] [clean] [dirty]
↑
DBWnがここから書き出す
CKPT(Checkpoint)プロセスとの役割分担
OracleにはDBWnとは別にCKPTプロセスがあります:
DBWn: ダーティバッファをデータファイルに書き出す
→ 実際のI/Oを行う
CKPT: チェックポイント情報を制御ファイルとデータファイルヘッダに記録する
→ DBWnに書き出しを指示する
→ 自分ではI/Oしない
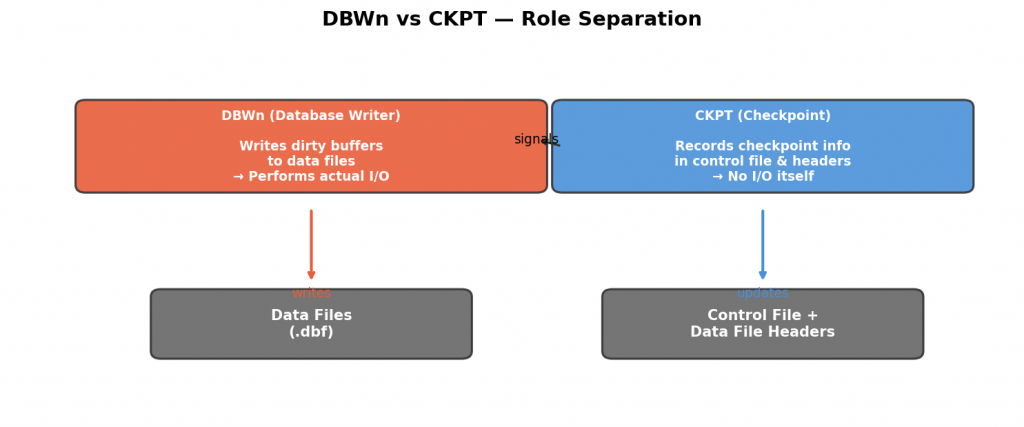
InnoDBではCheckpointerの役割がpage cleanerに統合されていますが、Oracleでは明確に分離されています。
3つのDBMSのフラッシュ比較
| InnoDB | PostgreSQL | Oracle | |
|---|---|---|---|
| 書き出しプロセス | page cleaner | BGWriter | DBWn |
| チェックポイント | 同上 | Checkpointer | CKPT + DBWn |
| ダーティ管理 | Flush List(LSN順) | なし(配列走査) | Checkpoint Queue(RBA順) |
| 書き出し量の決定 | 計算式(4要素) | バッファ割り当て速度予測 | 内部アルゴリズム(非公開) |
| 緊急フラッシュ | Single Flush | victim書き出し | サーバープロセスがDBWnに要求 |
ラッチとロック:Oracleの同時実行制御
Oracleでは、メモリ構造の保護に**ラッチ(Latch)とロック(Lock)**を使い分けます。ラッチはCPUレベルの超短期ロック(スピンロック)、ロックはより長期の排他制御です。
Buffer Cacheに関わる主要なラッチ
- Cache Buffer Chains ラッチ
- 保護対象:Hash Chain(ブロック検索時)
- 粒度:複数のHash Chainで1つのラッチを共有
- 競合時の待機イベント:latch: cache buffer chains
- InnoDB の Hash Map Lock、PostgreSQL の BufMappingLock に相当
- Cache Buffer LRU Chain ラッチ
- 保護対象:LRU Listの操作(挿入・削除・移動)
- 競合時の待機イベント:latch: cache buffers lru chain
- InnoDB の LRU List Mutex に相当
- Checkpoint Queue ラッチ
- 保護対象:Checkpoint Queueの操作
- 競合時の待機イベント:latch: checkpoint queue latch
- InnoDB の Flush List Mutex に相当
Buffer Lock(Buffer Pin)
ラッチとは別に、バッファの内容を保護するBuffer Lockがあります:
- Buffer Lock モード
- Shared (S): 読み取り用。複数セッションが同時に保持可能
- Exclusive (X): 書き込み用。1セッションだけが保持
- 競合時の待機イベント:buffer busy waits
- InnoDB の Page Frame Lock、PostgreSQL の Buffer Content Lock に相当
buffer busy waitsはOracleのパフォーマンスチューニングでよく見る待機イベントです。同じブロックに対する読み書きの競合が原因です。
ラッチ競合の確認方法
-- ラッチの競合状況を確認
SELECT name, gets, misses, sleeps,
ROUND(misses/NULLIF(gets,0)*100, 2) AS miss_pct
FROM V$LATCH
WHERE name IN (
'cache buffer chains',
'cache buffers lru chain',
'checkpoint queue latch'
)
ORDER BY misses DESC;
-- ホットブロックの特定(cache buffer chains競合時)
SELECT o.object_name, o.object_type, bh.tch, COUNT(*) AS buffers
FROM X$BH bh
JOIN DBA_OBJECTS o ON o.data_object_id = bh.OBJ
WHERE bh.tch > 10
GROUP BY o.object_name, o.object_type, bh.tch
ORDER BY bh.tch DESC;3つのDBMSのロック比較
| 役割 | InnoDB | PostgreSQL | Oracle |
|---|---|---|---|
| ハッシュテーブル | Hash Map Lock(16分割) | BufMappingLock(128分割) | Cache Buffer Chains ラッチ |
| LRU/リスト | LRU List Mutex | buffer_strategy_lock | Cache Buffer LRU Chain ラッチ |
| バッファヘッダ | Block Mutex | BM_LOCKED ビット | ラッチ内で処理 |
| ページデータ | Page Frame Lock | Content Lock | Buffer Lock (S/X) |
| ダーティリスト | Flush List Mutex | なし | Checkpoint Queue ラッチ |
| 競合の可視化 | SHOW ENGINE INNODB STATUS | pg_stat_activity | V$LATCH, V$SESSION_WAIT |
Oracleの強みは待機イベントの可視性です。V$SESSION_WAITやV$ACTIVE_SESSION_HISTORY(ASH)で、どのセッションがどのラッチで待っているかをリアルタイムに確認できます。InnoDBやPostgreSQLでは同等の情報を得るのがやや難しいです。
まとめ
この記事では、Oracle Buffer Cacheの内部構造を、InnoDB・PostgreSQLとの比較を交えて解説しました。
| テーマ | Oracle | InnoDB | PostgreSQL |
|---|---|---|---|
| 置換アルゴリズム | LRU + Touch Count | LRU(New/Old Sublist) | Clock Sweep |
| スキャン耐性 | Direct Path Read | New/Old Sublist | Ring Buffer |
| ダーティ管理 | Checkpoint Queue | Flush List | なし |
| 書き出し | DBWn + CKPT | page cleaner | BGWriter + Checkpointer |
| プール分割 | Default/Keep/Recycle | 単一(インスタンス分割) | 単一 |
| 可観測性 | X$BH, V$LATCH, ASH | SHOW ENGINE STATUS | pg_buffercache |
3つのDBMSを比較して見えてくるのは、同じ問題(ディスクI/Oの最小化、スキャン耐性、同時実行制御)に対して、それぞれ異なるアプローチを取っていることです:
- InnoDB:リスト構造を積極的に使い、情報を整理して持つ
- PostgreSQL:構造を最小限にして、必要なときに走査する
- Oracle:豊富なメタデータ(Touch Count、待機イベント)で可観測性を重視する
どれが「正解」ということではなく、各DBMSの全体設計(ストレージエンジン、WAL/REDO設計、プロセスモデル)に合わせた合理的な選択です。

コメント